Análisis de segmentación y caracterización de clústeres
Author
Sergi Ramirez Mitjans
1 Objetivo
Este documento realiza el profiling completo de un clustering jerárquico aplicado sobre una base de datos con variables mixtas (numéricas y categóricas). El flujo sigue estas fases:
Carga y preparación de los datos.
Cálculo de distancias de Gower para datos mixtos.
Clustering jerárquico con criterio Ward.
Asignación de individuos a clústeres.
Fase 1 de profiling: detección de variables significativas.
Cálculo de centroides/modas por clúster.
Fase 2 de profiling: significación de modalidades mediante enfoque de Lebart.
for (cV in vars_cat_a_graficar) {cat("### ", cV, "\n\n", sep ="") tabla <-data.frame(table(dades[[cV]], dades$cluster))colnames(tabla) <-c("modalidad", "cluster", "Freq") grafico <-ggplot(tabla, aes(x = modalidad, y = Freq, fill = cluster)) +geom_bar(stat ="identity", position ="dodge") +labs(title =paste("Distribución de", cV, "por clúster"), x = cV, y ="Frecuencia") +theme_minimal() +theme(axis.text.x =element_text(angle =45, hjust =1))print(grafico)cat("\n")}
4.2.4 Gender
### Item.Purchased
### Category
### Location
### Size
### Color
### Season
### Subscription.Status
### Shipping.Type
### Discount.Applied
### Promo.Code.Used
### Payment.Method
### Frequency.of.Purchases
4.3 Centroides y modas por clúster
4.3.1 Variables numéricas significativas
Mostrar código
datosAnalizarNum <- dades[, intersect(variablesPasanFase1, varNum), drop =FALSE]if (ncol(datosAnalizarNum) >0) { psych::describeBy(datosAnalizarNum, dades$cluster, mat =TRUE)} else {cat("No hay variables numéricas significativas en la fase 1.")}
No hay variables numéricas significativas en la fase 1.
4.3.2 Variables categóricas significativas: moda por clúster
Mostrar código
variablesAnalizarCAT <-intersect(variablesPasanFase1, varCat)listaModa <-list()if (length(variablesAnalizarCAT) >0) {for (vC in variablesAnalizarCAT) { tabla <-data.frame(table(dades[[vC]], dades$cluster))colnames(tabla) <-c("modalidad", "cluster", "Freq") calModa <- tabla |> dplyr::group_by(cluster) |> dplyr::filter(Freq ==max(Freq)) |> dplyr::select(modalidad, cluster, Freq) |>as.data.frame() listaModa[[vC]] <- calModa } listaModa} else {cat("No hay variables categóricas significativas en la fase 1.")}
4.4 Fase 2 del profiling: significación de modalidades (Lebart)
La segunda fase profundiza en la interpretación de los clústeres identificando:
Qué medias numéricas caracterizan más a cada grupo.
Qué modalidades categóricas están sobrerrepresentadas o infrarrepresentadas.
4.4.1 Test de Lebart
El test de Lebart es un contraste estadístico utilizado para comparar proporciones o medias observadas con valores teóricos o esperados.
Se utiliza frecuentemente en análisis de datos y minería de datos para verificar si un grupo presenta un comportamiento significativamente diferente del esperado.
Existen dos versiones habituales:
Test de Lebart para proporciones
Test de Lebart para medias
4.4.1.1 Test de Lebart para proporciones
Este test se utiliza para comprobar si la proporción observada en un grupo es significativamente diferente de una proporción esperada.
Hipótesis
\(H_{0}\): La proporción observada es igual a la proporción esperada
\[
p = p_{0}
\]
\(H_{1}\): La proporción observada es diferente de la esperada
\[
p \neq p_{0}
\]Estadístico del test
El test utiliza un estadístico basado en la distribución normal:
\[
Z = \frac{p - p_{0}}{\sqrt{\frac{p_{0}(1-p_{0})}{n}}}
\]
donde:
\(p\): proporción observada
\(p_{0}\): proporción esperada
\(n\): tamaño de la muestra
Decisión
Si p-value > 0.05\(\rightarrow\) No rechazamos \(H_{0}\)
Si p-value ≤ 0.05\(\rightarrow\) Rechazamos \(H_{0}\)
4.4.1.2 Test de Lebart para medias
El test de Lebart para medias se utiliza para comprobar si la media observada de un grupo es diferente de una media teórica o esperada.
Este contraste es conceptualmente similar a un test Z para medias.
Hipótesis
\(H_{0}\): La media observada es igual a la media esperada
\[
\mu = \mu_{0}
\]
\(H_{1}\): La media observada es diferente de la esperada
\[
\mu \neq \mu_{0}
\]Estadístico del test
El test utiliza un estadístico basado en la distribución normal:
\[
Z = \frac{\bar{x} - \mu_{0}}{\frac{s}{\sqrt{n}}}
\]
donde:
\(\bar{x}\): media observada
\(\mu_{0}\): media esperada
\(s\): desviación estándar
\(n\): tamaño de la muestra
Decisión
Si p-value > 0.05\(\rightarrow\) No rechazamos \(H_{0}\)
Si p-value ≤ 0.05\(\rightarrow\) Rechazamos \(H_{0}\)
sig <- tablaFase1 |> dplyr::filter(significativa =="Sí")sig
4.5.2 Resumen interpretativo
Mostrar código
cat("Número total de variables analizadas:", length(columnasValidar), "\n")
Número total de variables analizadas: 17
Mostrar código
cat("Variables significativas en fase 1:", length(variablesPasanFase1), "\n\n")
Variables significativas en fase 1: 4
Mostrar código
if (length(variablesPasanFase1) >0) {cat("Variables que mejor diferencian los clústeres:\n")cat(paste0("- ", variablesPasanFase1, collapse ="\n"))} else {cat("No se han detectado variables significativas con el umbral p <= 0.05.")}
Variables que mejor diferencian los clústeres:
- Gender
- Subscription.Status
- Discount.Applied
- Promo.Code.Used
Aquesta web està creada por Dante Conti y Sergi Ramírez, (c) 2026
Source Code
---title: "Profiling de un clustering sobre datos mixtos"subtitle: "Análisis de segmentación y caracterización de clústeres"author: "Sergi Ramirez Mitjans"format: html: theme: cosmo toc: true toc-depth: 3 number-sections: true code-fold: show code-summary: "Mostrar código" embed-resources: true code-tools: true df-print: pagedexecute: echo: true warning: false message: false error: false---```{r}#| label: setup#| include: false# Paquetes necesariospaquetes <-c("dendextend", "NbClust", "cluster", "ggpubr", "FactoMineR","modeest", "FactoClass", "dplyr", "ggplot2", "fpc", "psych")new.packages <- paquetes[!(paquetes %in%installed.packages()[, "Package"])]if (length(new.packages) >0) install.packages(new.packages)invisible(lapply(paquetes, require, character.only =TRUE))# URL de datosurl <-"https://raw.githubusercontent.com/ramIA-lab/MLforEducation/refs/heads/main/material/clustering/shopping_behavior_updated.csv"# Carga de datos# Usamos stringsAsFactors = FALSE para controlar explícitamente la conversióndades <-read.csv(url, stringsAsFactors =FALSE)# Tipos de variablestipo <-sapply(dades, class)varNum <-names(tipo)[tipo %in%c("integer", "numeric")]varNum <-setdiff(varNum, "Customer.ID")varCat <-names(tipo)[tipo %in%c("character", "factor")]# Conversión de categóricas a factorfor (vC in varCat) dades[[vC]] <-as.factor(dades[[vC]])```# ObjetivoEste documento realiza el **profiling completo de un clustering jerárquico** aplicado sobre una base de datos con variables mixtas (numéricas y categóricas). El flujo sigue estas fases:1. **Carga y preparación de los datos**. 2. **Cálculo de distancias de Gower** para datos mixtos. 3. **Clustering jerárquico** con criterio Ward. 4. **Asignación de individuos a clústeres**. 5. **Fase 1 de profiling**: detección de variables significativas. 6. **Cálculo de centroides/modas por clúster**. 7. **Fase 2 de profiling**: significación de modalidades mediante enfoque de Lebart. # Vista general de los datos## Dimensiones y estructura```{r}#| label: estructura-datoslist(dimensiones =dim(dades),variables_numericas = varNum,variables_categoricas = varCat)```## Primeras filas```{r}#| label: head-datoshead(dades)```## Resumen descriptivo```{r}#| label: resumen-datossummary(dades)```# Clustering jerárquico sobre datos mixtos## Cálculo de distancias de Gower```{r}#| label: gowerdistancias <- cluster::daisy(dades, metric ="gower")distancias2 <- distancias^2cat("Número de observaciones:", nrow(dades), "\n")cat("Número de distancias almacenadas:", length(distancias), "\n")```## Construcción del dendrograma```{r}#| label: hclust#| fig-width: 11#| fig-height: 6hc <-hclust(distancias2, method ="ward.D2")plot(hc, main ="Dendrograma del clustering jerárquico", xlab ="", sub ="")```## Dendrograma coloreado para k = 2```{r}#| label: dendrograma-k2#| fig-width: 11#| fig-height: 6as.dendrogram(hc) |>set("branches_k_color", k =2) |>plot(main ="Dendrograma con ramas coloreadas (k = 2)")```## Corte del árbol y asignación de clúster```{r}#| label: corte-arboldades$cluster <-as.factor(cutree(hc, k =2))table(dades$cluster)```## Calidad interna básica del clustering```{r}#| label: stats-clusteringfpc::cluster.stats(distancias2, clustering =as.numeric(dades$cluster))```# Profiling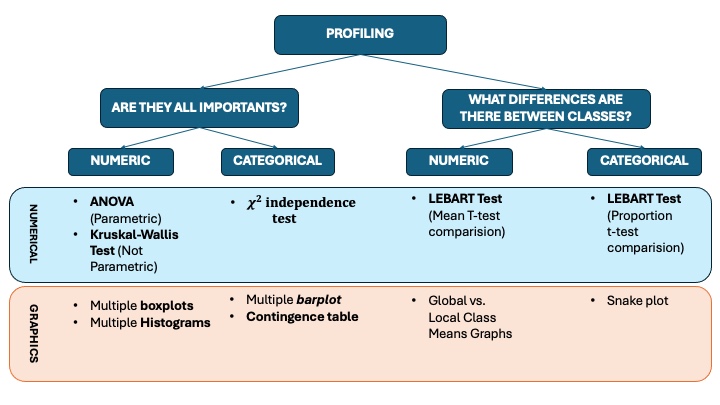{fig-align="center"}## Fase 1 del profiling: variables que diferencian los gruposEn esta fase se identifican las variables que discriminan significativamente entre clústeres.- Para variables **numéricas**: - Se evalúa normalidad con **Shapiro-Wilk**. - Si hay normalidad, se aplica **ANOVA**. - Si no hay normalidad, se aplica **Kruskal-Wallis**.- Para variables **categóricas**: - Se aplica **Chi-cuadrado de independencia**.### Test de Normalidad: **Shapiro-Wilk**Los **tests de normalidad** sirven para comprobar si una variable sigue una **distribución normal**.Esto es importante porque muchos métodos estadísticos (como ANOVA) requieren normalidad.**Hipótesis*** $H_{0}$: Los datos siguen una distribución Normal * $H_{1}$: Los datos **NO** siguen una distribución Normal **Decisión*** Si **p-value > 0.05** $\rightarrow$ No rechazamos $H_{0}$ $\rightarrow$ Los datos pueden considerarse normales* Si **p-value ≤ 0.05** $\rightarrow$ Rechazamos $H_{0}$ $\rightarrow$ Los datos no son normales### ANOVA (Analysis of Variance)El **ANOVA** se utiliza para comparar la **media de tres o más grupos**.**Hipótesis*** $H_{0}$: Todas las medias son iguales$$\mu_{1} = \mu_{2} = \mu_{3}$$* $H_{1}$: Al menos una media es diferente**Supuestos**Para aplicar ANOVA: 1. Normalidad2. Independencia3. Homogeneidad de varianzas**Decisión*** Si **p-value > 0.05** $\rightarrow$ No rechazamos $H_{0}$ $\rightarrow$ Las medias son similares* Si **p-value ≤ 0.05** $\rightarrow$ Rechazamos $H_{0}$ $\rightarrow$ Alguna media es distinta### Test de Kruskal-WallisEl Kruskal-Wallis es la alternativa no paramétrica al ANOVA.Se usa cuando:* Los datos no son normales* O las varianzas no son homogéneas.En lugar de comparar medias, compara rangos.**Hipótesis*** $H_{0}$: Las distribuciones de los grupos son iguales* $H_{1}$: Al menos un grupo es diferente**Decisión*** Si **p-value > 0.05** $\rightarrow$ No rechazamos $H_{0}$ * Si **p-value ≤ 0.05** $\rightarrow$ Rechazamos $H_{0}$ ### Test Chi-cuadrado de independenciaEl test Chi-cuadrado sirve para analizar si dos variables categóricas están relacionadas.**Hipótesis*** $H_{0}$: Las variables son independientes* $H_{1}$: Las variables están relacionadas**Decisión*** Si **p-value > 0.05** $\rightarrow$ No rechazamos $H_{0}$ $\rightarrow$ No hay relación* Si **p-value ≤ 0.05** $\rightarrow$ Rechazamos $H_{0}$ $\rightarrow$ Existe relación```{r}#| label: fase1-calculocolumnasValidar <-setdiff(colnames(dades), c("Customer.ID", "cluster"))variablesPasanFase1 <-c()resultadosFase1 <-list()for (cV in columnasValidar) { clase_var <-class(dades[[cV]])[1]# =====================# VARIABLES NUMÉRICAS# =====================if (clase_var %in%c("integer", "numeric")) { shapiro_ok <-FALSE p_shapiro <-NA_real_ metodo <-NA_character_ p_valor <-NA_real_ detalle <-NULL# Shapiro falla si hay demasiados datos o valores constantes; controlamos eso. sh <-tryCatch(shapiro.test(dades[[cV]]), error =function(e) NULL)if (!is.null(sh)) { p_shapiro <- sh$p.value shapiro_ok <- p_shapiro >0.05 }if (!is.na(p_shapiro) && shapiro_ok) { test_obj <-aov(dades[[cV]] ~ dades$cluster) detalle <-summary(test_obj) p_valor <- detalle[[1]][["Pr(>F)"]][1] metodo <-"ANOVA" } else { test_obj <-kruskal.test(dades[[cV]] ~ dades$cluster) detalle <- test_obj p_valor <- test_obj$p.value metodo <-"Kruskal-Wallis" }if (!is.na(p_valor) && p_valor <=0.05) { variablesPasanFase1 <-c(variablesPasanFase1, cV) } resultadosFase1[[cV]] <-list(tipo ="Numérica",metodo = metodo,p_shapiro = p_shapiro,p_valor = p_valor,detalle = detalle ) }# =======================# VARIABLES CATEGÓRICAS# =======================if (clase_var %in%c("factor", "character")) { test_obj <-suppressWarnings(chisq.test(dades[[cV]], dades$cluster)) p_valor <- test_obj$p.valueif (!is.na(p_valor) && p_valor <=0.05) { variablesPasanFase1 <-c(variablesPasanFase1, cV) } resultadosFase1[[cV]] <-list(tipo ="Categórica",metodo ="Chi-cuadrado",p_valor = p_valor,detalle = test_obj ) }}variablesPasanFase1 <-unique(variablesPasanFase1)variablesPasanFase1```### Tabla resumen de significación```{r}#| label: tabla-fase1tablaFase1 <- dplyr::bind_rows(lapply(names(resultadosFase1), function(v) { x <- resultadosFase1[[v]]data.frame(variable = v,tipo = x$tipo,metodo = x$metodo,p_shapiro =ifelse(is.null(x$p_shapiro), NA, x$p_shapiro),p_valor = x$p_valor,significativa =ifelse(!is.na(x$p_valor) & x$p_valor <=0.05, "Sí", "No") )}))tablaFase1 <- tablaFase1 |>arrange(tipo, p_valor)tablaFase1```## Visualización de variables del profiling### Variables numéricas```{r}#| label: nombres-numericasvars_num_a_graficar <- columnasValidar[sapply(dades[columnasValidar], function(x) class(x)[1] %in%c("integer", "numeric"))]vars_num_a_graficar``````{r}#| label: graficos-numericos#| results: asisfor (cV in vars_num_a_graficar) {cat("### ", cV, "\n\n", sep ="") graficoBoxplot <- ggpubr::ggboxplot(dades, "cluster", cV, fill ="cluster") graficoHistograma <- ggpubr::gghistogram( dades, x = cV,add ="mean", rug =TRUE,color ="cluster", fill ="cluster" ) grafico <- ggpubr::ggarrange( graficoBoxplot, graficoHistograma,heights =c(2, 0.7),ncol =2, nrow =1, align ="v" )print(grafico)cat("\n")}```### Variables categóricas```{r}#| label: nombres-categoricasvars_cat_a_graficar <- columnasValidar[sapply(dades[columnasValidar], function(x) class(x)[1] %in%c("factor", "character"))]vars_cat_a_graficar``````{r}#| label: graficos-categoricos#| results: asis#| fig-width: 10#| fig-height: 5for (cV in vars_cat_a_graficar) {cat("### ", cV, "\n\n", sep ="") tabla <-data.frame(table(dades[[cV]], dades$cluster))colnames(tabla) <-c("modalidad", "cluster", "Freq") grafico <-ggplot(tabla, aes(x = modalidad, y = Freq, fill = cluster)) +geom_bar(stat ="identity", position ="dodge") +labs(title =paste("Distribución de", cV, "por clúster"), x = cV, y ="Frecuencia") +theme_minimal() +theme(axis.text.x =element_text(angle =45, hjust =1))print(grafico)cat("\n")}```## Centroides y modas por clúster### Variables numéricas significativas```{r}#| label: centroides-numericosdatosAnalizarNum <- dades[, intersect(variablesPasanFase1, varNum), drop =FALSE]if (ncol(datosAnalizarNum) >0) { psych::describeBy(datosAnalizarNum, dades$cluster, mat =TRUE)} else {cat("No hay variables numéricas significativas en la fase 1.")}```### Variables categóricas significativas: moda por clúster```{r}#| label: modas-categoricasvariablesAnalizarCAT <-intersect(variablesPasanFase1, varCat)listaModa <-list()if (length(variablesAnalizarCAT) >0) {for (vC in variablesAnalizarCAT) { tabla <-data.frame(table(dades[[vC]], dades$cluster))colnames(tabla) <-c("modalidad", "cluster", "Freq") calModa <- tabla |> dplyr::group_by(cluster) |> dplyr::filter(Freq ==max(Freq)) |> dplyr::select(modalidad, cluster, Freq) |>as.data.frame() listaModa[[vC]] <- calModa } listaModa} else {cat("No hay variables categóricas significativas en la fase 1.")}```## Fase 2 del profiling: significación de modalidades (Lebart)La segunda fase profundiza en la interpretación de los clústeres identificando:- **Qué medias numéricas** caracterizan más a cada grupo.- **Qué modalidades categóricas** están sobrerrepresentadas o infrarrepresentadas.### Test de LebartEl test de Lebart es un contraste estadístico utilizado para comparar proporciones o medias observadas con valores teóricos o esperados.Se utiliza frecuentemente en análisis de datos y minería de datos para verificar si un grupo presenta un comportamiento significativamente diferente del esperado.Existen dos versiones habituales:* Test de Lebart para proporciones* Test de Lebart para medias#### Test de Lebart para proporcionesEste test se utiliza para comprobar si la proporción observada en un grupo es significativamente diferente de una proporción esperada.**Hipótesis*** $H_{0}$: La proporción observada es igual a la proporción esperada$$p = p_{0}$$* $H_{1}$: La proporción observada es diferente de la esperada$$p \neq p_{0}$$**Estadístico del test**El test utiliza un estadístico basado en la distribución normal:$$Z = \frac{p - p_{0}}{\sqrt{\frac{p_{0}(1-p_{0})}{n}}}$$donde:* $p$: proporción observada * $p_{0}$: proporción esperada* $n$: tamaño de la muestra**Decisión*** Si **p-value > 0.05** $\rightarrow$ No rechazamos $H_{0}$ * Si **p-value ≤ 0.05** $\rightarrow$ Rechazamos $H_{0}$ #### Test de Lebart para medias El test de Lebart para medias se utiliza para comprobar si la media observada de un grupo es diferente de una media teórica o esperada.Este contraste es conceptualmente similar a un test Z para medias.**Hipótesis*** $H_{0}$: La media observada es igual a la media esperada$$\mu = \mu_{0}$$* $H_{1}$: La media observada es diferente de la esperada$$\mu \neq \mu_{0}$$**Estadístico del test**El test utiliza un estadístico basado en la distribución normal:$$Z = \frac{\bar{x} - \mu_{0}}{\frac{s}{\sqrt{n}}}$$donde:* $\bar{x}$: media observada* $\mu_{0}$: media esperada* $s$: desviación estándar* $n$: tamaño de la muestra**Decisión*** Si **p-value > 0.05** $\rightarrow$ No rechazamos $H_{0}$ * Si **p-value ≤ 0.05** $\rightarrow$ Rechazamos $H_{0}$ ### Resultados globales con `catdes()````{r}#| label: catdes-globalres_catdes <- FactoMineR::catdes(dades, num.var =ncol(dades))res_catdes```### Gráfico de variables cuantitativas```{r}#| label: catdes-quanti#| fig-width: 11#| fig-height: 7plot(res_catdes, show ="quanti", col.upper ="red", col.lower ="blue", barplot =TRUE, cex.names =1)```### Gráfico de variables cualitativas```{r}#| label: catdes-quali#| fig-width: 11#| fig-height: 7plot(res_catdes, show ="quali", col.upper ="red", col.lower ="blue", barplot =FALSE, cex.names =1.2)```### Gráfico conjunto```{r}#| label: catdes-all#| fig-width: 11#| fig-height: 7plot(res_catdes, show ="all", col.upper ="red", col.lower ="blue", barplot =FALSE, cex.names =1.2)```### Test de Lebart para variables numéricas```{r}#| label: lebart-numericasdadesF <- FactoClass::Fac.Num(dades)dades_num <-cbind(dadesF$numeric, dadesF$integer)class_cluster <- dadesF$factor$clusterif (ncol(dades_num) >0) { prueba_num <-cluster.carac( dades_num, class_cluster,tipo.v ="co", v.lim =1.96, neg =TRUE ) prueba_num} else {cat("No hay variables numéricas disponibles para el test de Lebart de medias.")}```### Test de Lebart para variables categóricas```{r}#| label: lebart-categoricasdades_cat <- dadesF$factor |> dplyr::select(-cluster)class_cluster <- dadesF$factor$clusterif (ncol(dades_cat) >0) { prueba_cat <-cluster.carac( dades_cat, class_cluster,tipo.v ="ca", v.lim =1.96, neg =FALSE ) prueba_cat} else {cat("No hay variables categóricas disponibles para el test de Lebart de proporciones.")}```## Conclusiones automáticas del profiling### Variables significativas detectadas```{r}#| label: conclusiones-significativassig <- tablaFase1 |> dplyr::filter(significativa =="Sí")sig```### Resumen interpretativo```{r}#| label: resumen-interpretativocat("Número total de variables analizadas:", length(columnasValidar), "\n")cat("Variables significativas en fase 1:", length(variablesPasanFase1), "\n\n")if (length(variablesPasanFase1) >0) {cat("Variables que mejor diferencian los clústeres:\n")cat(paste0("- ", variablesPasanFase1, collapse ="\n"))} else {cat("No se han detectado variables significativas con el umbral p <= 0.05.")}```




 ### Purchase.Amount..USD.
### Purchase.Amount..USD. ### Review.Rating
### Review.Rating ### Previous.Purchases
### Previous.Purchases
 ### Item.Purchased
### Item.Purchased ### Category
### Category ### Location
### Location ### Size
### Size ### Color
### Color ### Season
### Season ### Subscription.Status
### Subscription.Status ### Shipping.Type
### Shipping.Type ### Discount.Applied
### Discount.Applied ### Promo.Code.Used
### Promo.Code.Used ### Payment.Method
### Payment.Method ### Frequency.of.Purchases
### Frequency.of.Purchases



