El Análisis de Componentes Principales (ACP) es una técnica de reducción de dimensionalidad que transforma un conjunto de variables posiblemente correlacionadas en un conjunto más pequeño de variables no correlacionadas llamadas componentes principales (CPs).
Objetivos típicos:
Capturar la mayor varianza con el menor número de componentes.
Descorrelacionar variables y simplificar la estructura.
Facilitar visualización, preprocesamiento para modelos y compresión.
Intuición: el ACP encuentra direcciones (vectores) en el espacio de los datos que maximizan la varianza. Esas direcciones son los autovectores de la matriz de covarianzas (o correlaciones), y la varianza capturada por cada componente viene dada por su autovalor.
2 Supuestos y buenas prácticas
Estandarización: si las variables tienen escalas diferentes, estandariza (media 0, var 1).
Linealidad: PCA capta relaciones lineales.
Outliers: pueden dominar la varianza; considera limpiarlos o usar variantes robustas.
Datos numéricos: para variables categóricas puras, usa técnicas específicas (MCA/FAMD).
3 Flujo de trabajo (resumen)
Estandarizar (opcional pero recomendado).
Ajustar ACP sobre matriz estandarizada.
Evaluar varianza explicada y elegir k componentes.
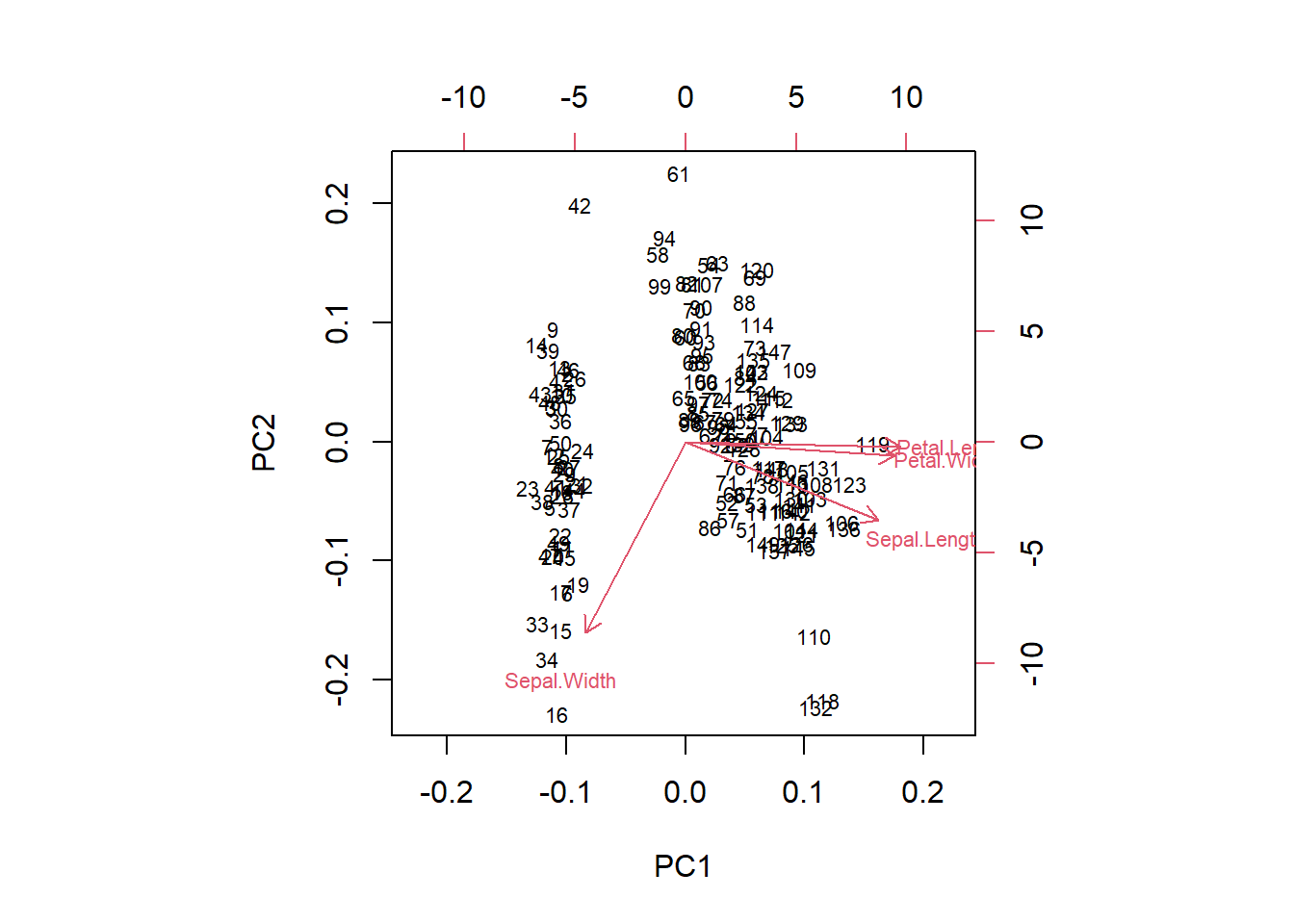
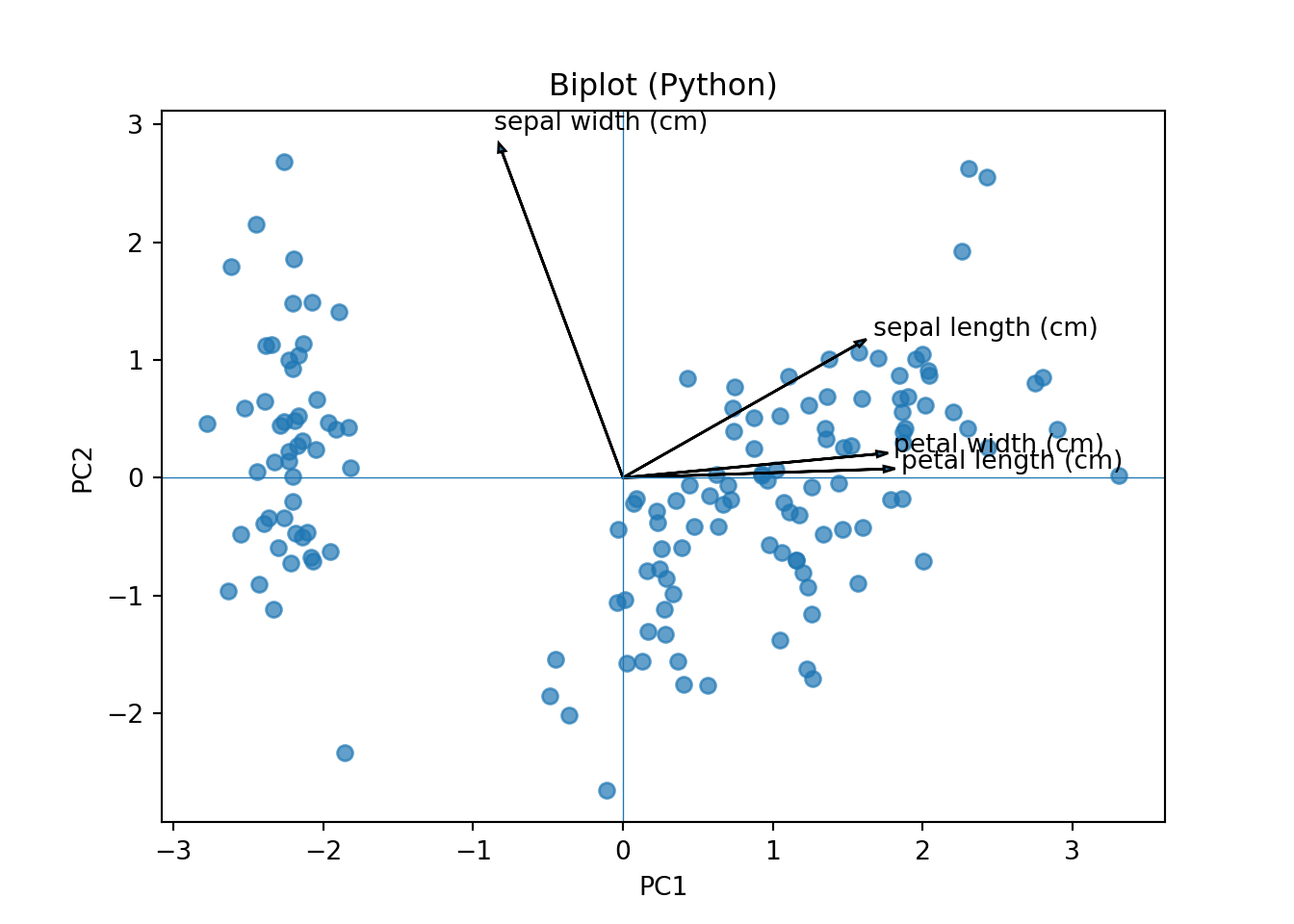
Inspeccionar cargas (loadings) y scores.
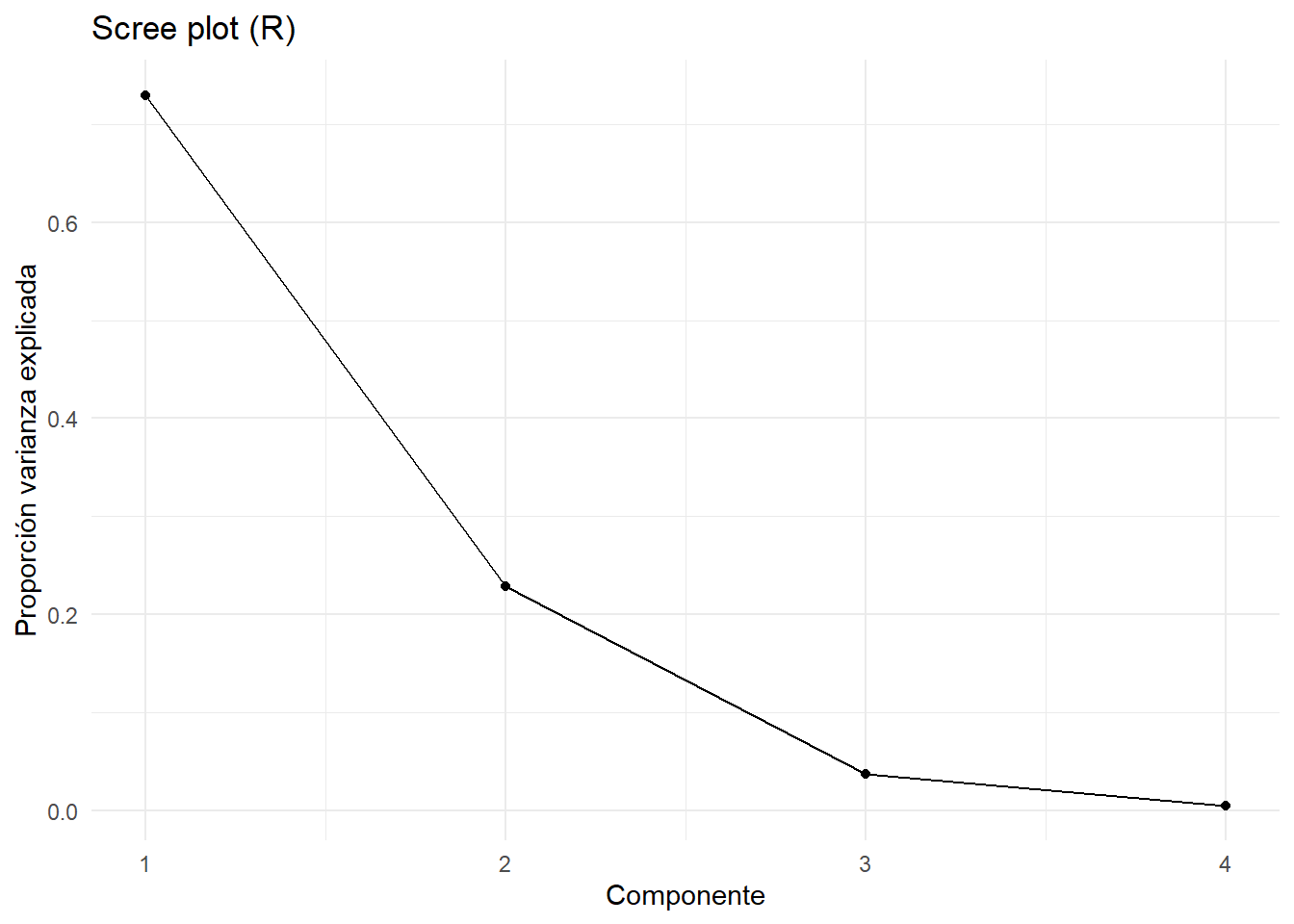
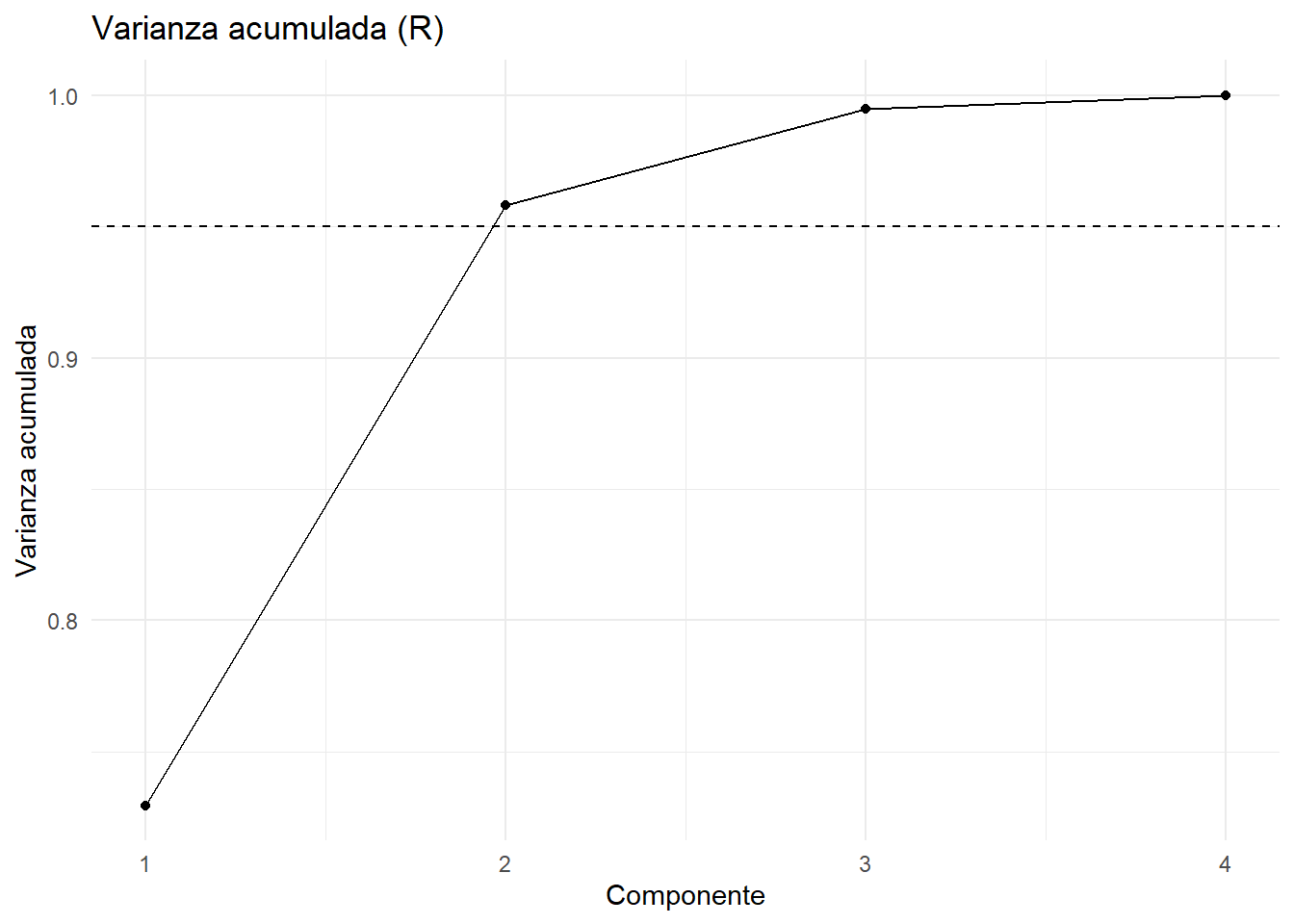
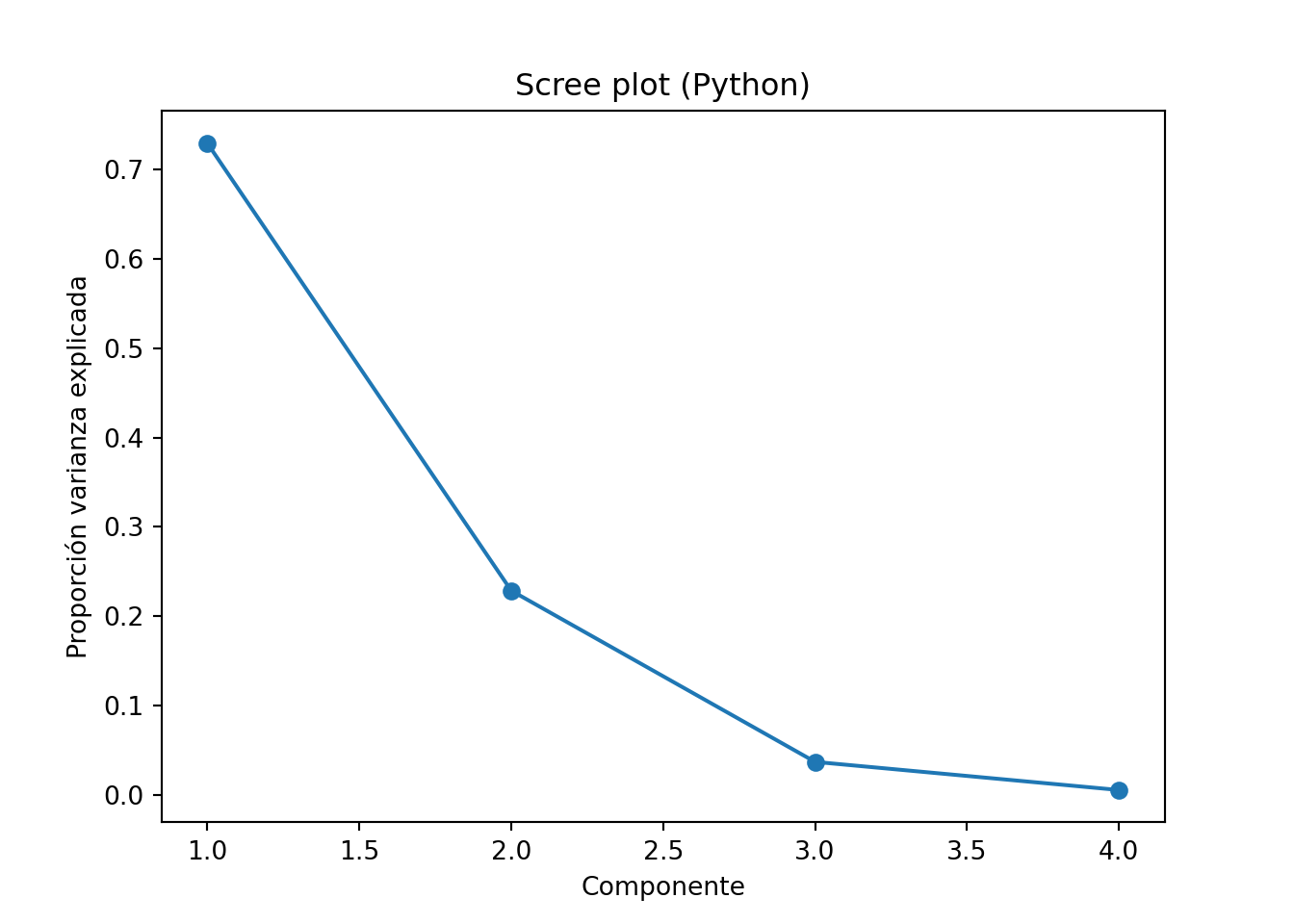
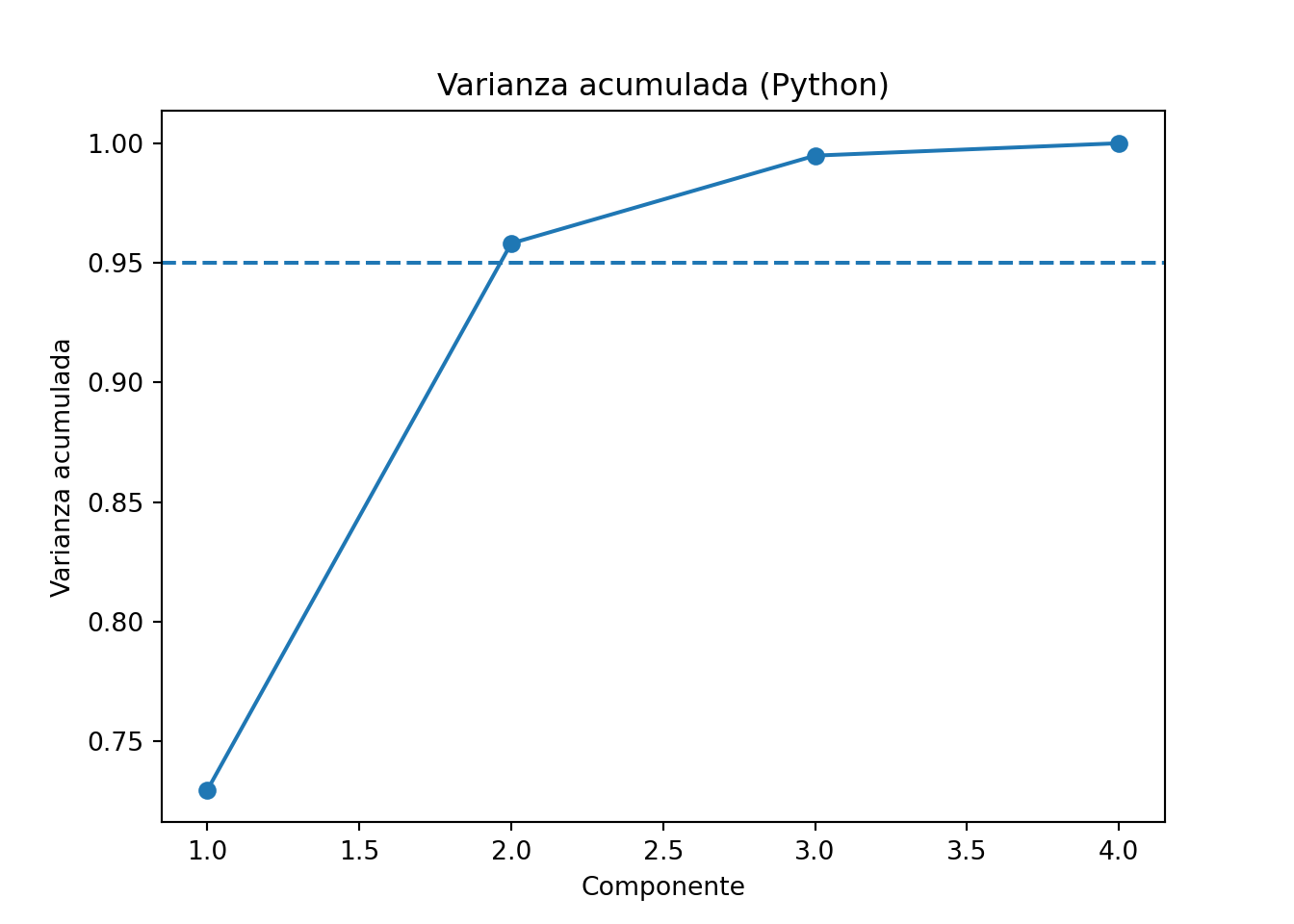
Visualizar: scree plot, biplot.
Proyectar nuevos datos y (si aplica) reconstruir.
4 Dataset de ejemplo
Usaremos el clásico Iris (4 variables numéricas, 3 especies).
En R: datasets::iris.
En Python: sklearn.datasets.load_iris().
from sklearn.decomposition import PCApca = PCA() # por defecto n_components = min(n_samples, n_features)pca.fit(X_scaled)
PCA()
In a Jupyter environment, please rerun this cell to show the HTML representation or trust the notebook. On GitHub, the HTML representation is unable to render, please try loading this page with nbviewer.org.
# Ejemplo con caret o tidymodels (aquí base con prcomp para simplicidad)# Generar componentes y usar los primeros k como featuresk <-2pc_df <-as.data.frame(scores[, 1:k])pc_df$Species <- iris$Specieshead(pc_df)
Vectores largos: variables con alta contribución al componente.
Ángulos pequeños entre vectores: variables correlacionadas.
Puntos (observaciones) próximos: perfiles similares en variables originales.
Signo de la carga: dirección de la relación con el componente.
11 Trucos y errores comunes
No estandarizar cuando hay escalas muy distintas distorsiona el resultado
Outliers: revisar o usar alternativas robustas (p. ej., robustbase en R, sklearn + métodos robustos).
Muchas variables: considerar PCA incremental si hay memoria limitada.
Interpretabilidad: PCA rota ejes de forma no supervisada, no siempre mapea a factores interpretables.
12 Referencias rápidas (concepto)
Componentes = autovectores de covarianzas/correlaciones; varianza = autovalores.
scores = X_estandarizado %*% loadings
Reconstrucción aproximada: X̂_est = scores_k %*% t(loadings_k); desestandarizar para volver a escala original.
Aquesta web està creada por Dante Conti y Sergi Ramírez, (c) 2026
Source Code
---title: "Anàlisis de Components Principals (ACP)"author: Dante Conti, Sergi Ramirez, (c) IDEAIdate: "`r Sys.Date()`"date-modified: "`r Sys.Date()`"toc: true# language: esnumber-sections: trueformat: html: theme: light: cerulean dark: darkly code-tools: trueeditor: visual#execute: # freeze: auto---# ¿Qué es el ACP?El **Análisis de Componentes Principales (ACP)** es una técnica de **reducción de dimensionalidad** que transforma un conjunto de variables posiblemente correlacionadas en un conjunto más pequeño de variables no correlacionadas llamadas **componentes principales (CPs)**.\Objetivos típicos:- Capturar la mayor **varianza** con el menor número de componentes.\- **Descorrelacionar** variables y simplificar la estructura.\- Facilitar **visualización**, **preprocesamiento** para modelos y **compresión**.> Intuición: el ACP encuentra direcciones (vectores) en el espacio de los datos que maximizan la varianza. Esas direcciones son los **autovectores** de la matriz de covarianzas (o correlaciones), y la varianza capturada por cada componente viene dada por su **autovalor**.# Supuestos y buenas prácticas- **Estandarización**: si las variables tienen escalas diferentes, estandariza (media 0, var 1).\- **Linealidad**: PCA capta relaciones lineales.\- **Outliers**: pueden dominar la varianza; considera limpiarlos o usar variantes robustas.\- **Datos numéricos**: para variables categóricas puras, usa técnicas específicas (MCA/FAMD).# Flujo de trabajo (resumen)1. Estandarizar (opcional pero recomendado).\2. Ajustar ACP sobre matriz estandarizada.\3. Evaluar **varianza explicada** y elegir k componentes.\4. Inspeccionar **cargas** (loadings) y **scores**.\5. Visualizar: **scree plot**, **biplot**.\6. Proyectar nuevos datos y (si aplica) reconstruir.# Dataset de ejemploUsaremos el clásico **Iris** (4 variables numéricas, 3 especies).\En R: `datasets::iris`.\En Python: `sklearn.datasets.load_iris()`.# Datos y estandarización::: panel-tabset## R```{r}# Paqueteslibrary(dplyr)library(ggplot2)# Cargar irisdata(iris)df <- iris %>%select(-Species) # solo numéricas# Estandarizar (media 0, sd 1)df_scaled <-scale(df)# Vista rápidaas_tibble(head(df)) %>%print(n=6)apply(df_scaled, 2, sd) # ~1```## Python```{python}import numpy as npimport pandas as pdfrom sklearn.datasets import load_irisfrom sklearn.preprocessing import StandardScaler# Cargar irisiris = load_iris()X = pd.DataFrame(iris.data, columns=iris.feature_names)y = pd.Series(iris.target, name="species") # 0,1,2# Estandarizarscaler = StandardScaler()X_scaled = scaler.fit_transform(X)# Vista rápidaX.head()np.std(X_scaled, axis=0) # ~1```:::# Ajuste del ACP::: panel-tabset## R```{r}# prcomp usa SVD; center=TRUE, scale.=TRUE también estandariza internamentepca <-prcomp(df, center =TRUE, scale. =TRUE)# Varianza explicadavar_exp <- pca$sdev^2var_exp_ratio <- var_exp /sum(var_exp)cum_exp_ratio <-cumsum(var_exp_ratio)var_exp_ratiocum_exp_ratio```## Python```{python}from sklearn.decomposition import PCApca = PCA() # por defecto n_components = min(n_samples, n_features)pca.fit(X_scaled)var_exp = pca.explained_variance_var_exp_ratio = pca.explained_variance_ratio_cum_exp_ratio = np.cumsum(var_exp_ratio)var_exp_ratio, cum_exp_ratio``````{python}import princedf = pd.DataFrame(X_scaled, columns=["col1", "col2", "col3", "col4"])pcaP = prince.PCA( n_components=3, n_iter=3, rescale_with_mean=True, rescale_with_std=True, copy=True, check_input=True, engine='sklearn', random_state=42)pcaP = pcaP.fit( df, sample_weight=None, column_weight=None, supplementary_columns=None)```:::# Scree plot y varianza acumulada::: panel-tabset## R```{r}scree_df <-data.frame(PC =paste0("PC", seq_along(var_exp_ratio)),VarExp = var_exp_ratio,CumExp = cum_exp_ratio)# Scree plotggplot(scree_df, aes(x =seq_along(VarExp), y = VarExp)) +geom_line() +geom_point() +labs(x ="Componente", y ="Proporción varianza explicada",title ="Scree plot (R)") +theme_minimal()# Varianza acumuladaggplot(scree_df, aes(x =seq_along(CumExp), y = CumExp)) +geom_line() +geom_point() +geom_hline(yintercept =0.95, linetype ="dashed") +labs(x ="Componente", y ="Varianza acumulada",title ="Varianza acumulada (R)") +theme_minimal()```## Python```{python}import matplotlib.pyplot as plt# Scree plotplt.figure()plt.plot(range(1, len(var_exp_ratio)+1), var_exp_ratio, marker="o")plt.xlabel("Componente")plt.ylabel("Proporción varianza explicada")plt.title("Scree plot (Python)")plt.show()# Varianza acumuladaplt.figure()plt.plot(range(1, len(cum_exp_ratio)+1), cum_exp_ratio, marker="o")plt.axhline(0.95, linestyle="--")plt.xlabel("Componente")plt.ylabel("Varianza acumulada")plt.title("Varianza acumulada (Python)")plt.show()```:::# Cargas (loadings) y scoresLas **cargas** indican cuánto contribuye cada variable a cada componente (correlaciones variable–componente).Los **scores** son las coordenadas de las observaciones en el espacio de componentes.::: panel-tabset## R```{r}# Cargasloadings <- pca$rotationround(loadings, 3)# Scoresscores <- pca$xhead(scores)# Biplot rápidobiplot(pca, cex =0.7) # base R```## Python```{python}# Cargas = vectores propios (componentes)loadings = pca.components_.T # shape: n_features x n_componentspd.DataFrame(loadings, index=iris.feature_names, columns=[f"PC{i+1}"for i inrange(loadings.shape[1])]).round(3)# Scores (transformación de los datos)scores = pca.transform(X_scaled)pd.DataFrame(scores, columns=[f"PC{i+1}"for i inrange(scores.shape[1])]).head()# Biplot sencillo (PC1 vs PC2)pc1, pc2 =0, 1plt.figure()plt.scatter(scores[:, pc1], scores[:, pc2], alpha=0.7)# Vectores de variablesfor i, feature inenumerate(iris.feature_names): plt.arrow(0, 0, loadings[i, pc1]*3, loadings[i, pc2]*3, head_width=0.05) plt.text(loadings[i, pc1]*3.2, loadings[i, pc2]*3.2, feature)plt.xlabel("PC1")plt.ylabel("PC2")plt.title("Biplot (Python)")plt.axhline(0, linewidth=0.5); plt.axvline(0, linewidth=0.5)plt.show()```:::## Elección de número de componentesCriterios habituales:1. **Codo** del scree plot.2. Umbral de **varianza acumulada** (p. ej., 90–95%).3. **Kaiser** (autovalores \> 1) cuando se usa matriz de correlaciones.4. **Validación** en tareas posteriores (clasificación/regresión).::: panel-tabset## R```{r}# Elegir k para alcanzar >= 95% varianza(k <-which(cum_exp_ratio >=0.95)[1])```## Python```{python}k =int(np.argmax(cum_exp_ratio >=0.95)) +1k```:::# Proyección y reconstrucción::: panel-tabset## R```{r}# Proyectar datos a k componentesk <-which(cum_exp_ratio >=0.95)[1]scores_k <- scores[, 1:k, drop =FALSE]# Reconstrucción aproximada (desde scores_k -> espacio original estandarizado)# X_std_hat = scores_k %*% t(loadings[,1:k])Xstd_hat <- scores_k %*%t(loadings[, 1:k])# "Desestandarizar" para volver a escala originalmeans <-attr(df_scaled, "scaled:center")sds <-attr(df_scaled, "scaled:scale")Xrec <-sweep(Xstd_hat, 2, sds, `*`)Xrec <-sweep(Xrec, 2, means, `+`)as_tibble(head(Xrec))```## Python```{python}k =int(np.argmax(cum_exp_ratio >=0.95)) +1scores_k = scores[:, :k]load_k = loadings[:, :k]# Reconstrucción en espacio estandarizadoXstd_hat = np.dot(scores_k, load_k.T)# DesestandarizarXrec = scaler.inverse_transform(Xstd_hat)pd.DataFrame(Xrec, columns=iris.feature_names).head()```:::# Pipeline para uso en modelosEn ML, es común encadenar **escalado + PCA** y luego un modelo.::: panel-tabset## R```{r}# Ejemplo con caret o tidymodels (aquí base con prcomp para simplicidad)# Generar componentes y usar los primeros k como featuresk <-2pc_df <-as.data.frame(scores[, 1:k])pc_df$Species <- iris$Specieshead(pc_df)```## Python```{python}from sklearn.pipeline import Pipelinefrom sklearn.linear_model import LogisticRegressionfrom sklearn.model_selection import cross_val_scorek =2pipe = Pipeline([ ("scaler", StandardScaler()), ("pca", PCA(n_components=k)), ("clf", LogisticRegression(max_iter=1000))])scores_cv = cross_val_score(pipe, X, y, cv=5)scores_cv.mean(), scores_cv.std()```:::## Interpretación de cargas y biplot- Vectores largos: variables con alta contribución al componente.- Ángulos pequeños entre vectores: variables **correlacionadas.**- Puntos (observaciones) próximos: perfiles similares en variables originales.- Signo de la carga: dirección de la relación con el componente.# Trucos y errores comunes- **No estandarizar** cuando hay escalas muy distintas distorsiona el resultado- **Outliers**: revisar o usar alternativas robustas (p. ej., `robustbase` en R, `sklearn` + métodos robustos).- **Muchas variables**: considerar **PCA incremental** si hay memoria limitada.- **Interpretabilidad**: PCA rota ejes de forma no supervisada, no siempre mapea a factores *interpretables*.# Referencias rápidas (concepto)- Componentes = autovectores de covarianzas/correlaciones; varianza = autovalores.- `scores = X_estandarizado %*% loadings`- Reconstrucción aproximada: `X̂_est = scores_k %*% t(loadings_k)`; desestandarizar para volver a escala original.