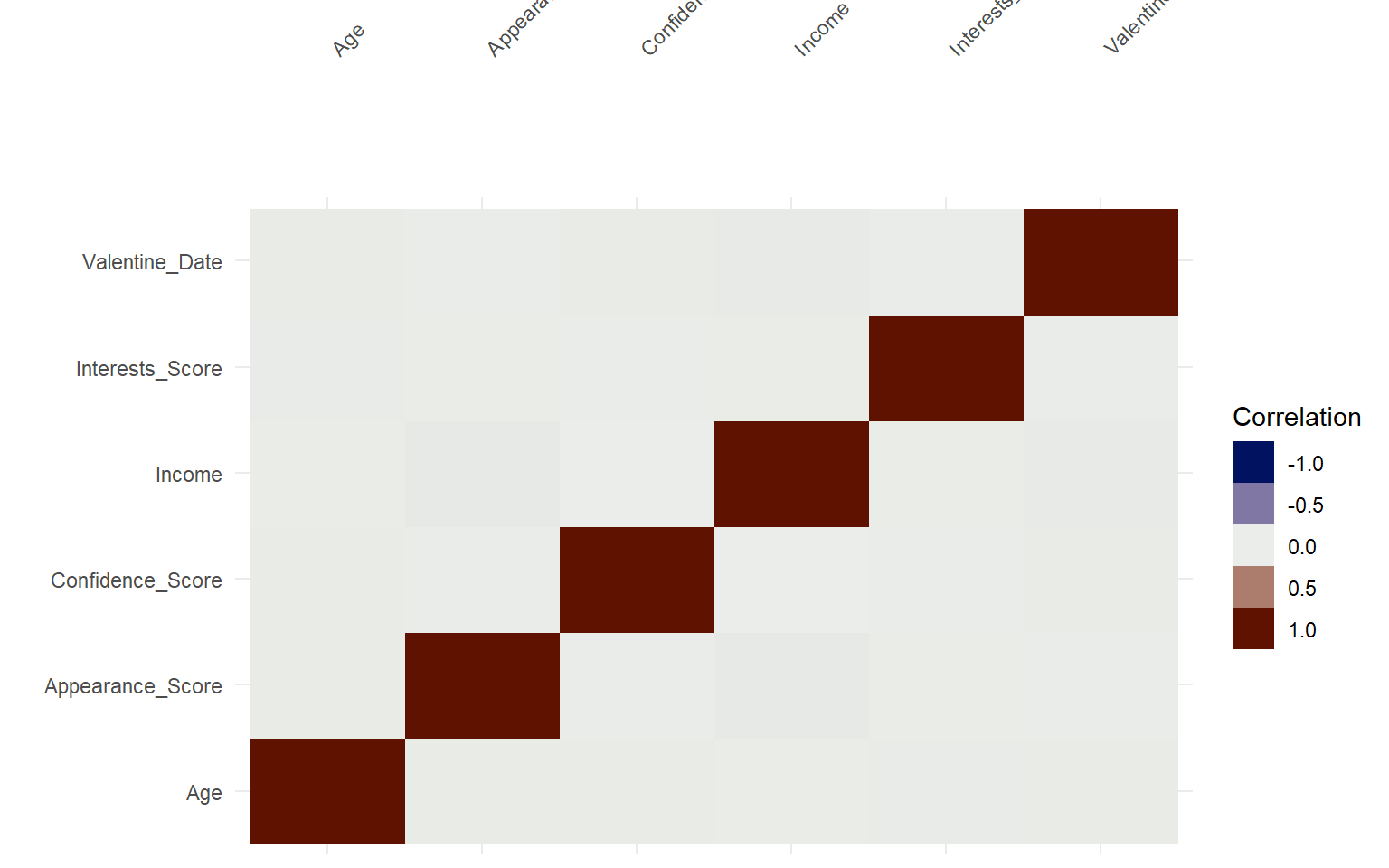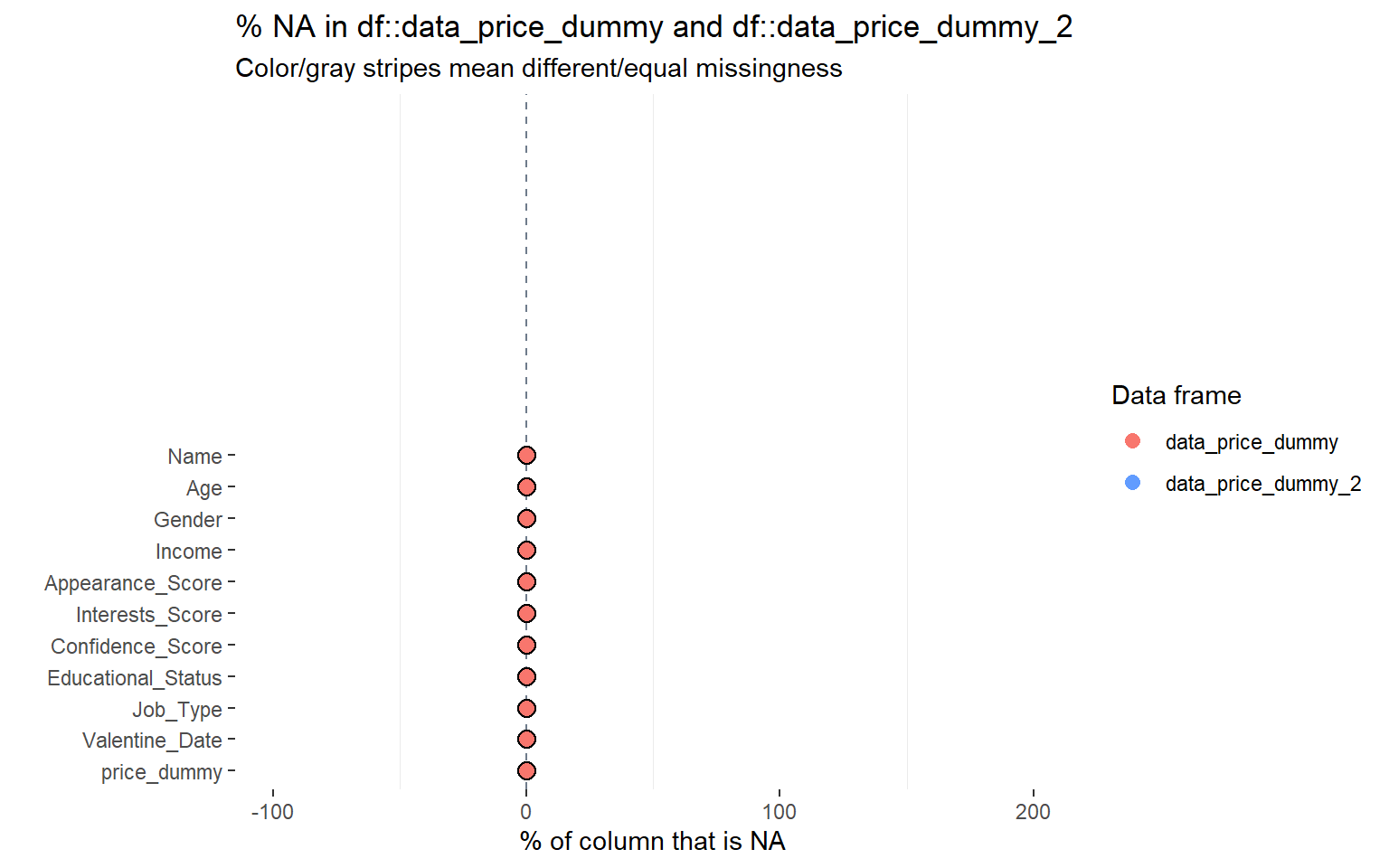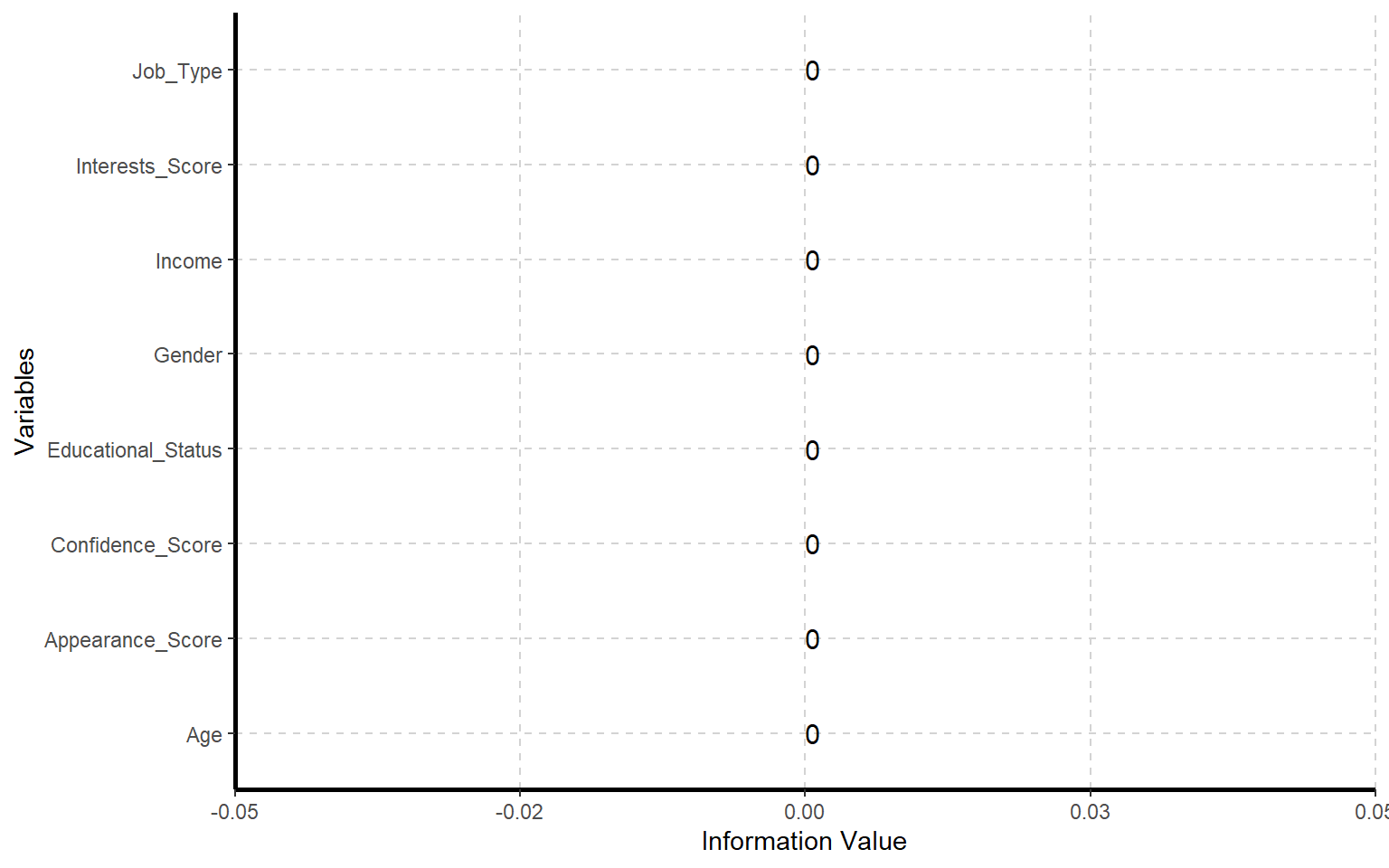En este script trabajamos la descriptiva automática o EDA (Exploratory Data Analysis) utilizando varias librerías de R especializadas en exploración rápida de datos.
El objetivo docente de esta práctica es que el alumnado sea capaz de:
entender la estructura de una base de datos antes de modelizar,
identificar variables numéricas y categóricas,
detectar valores perdidos,
estudiar correlaciones,
generar reportes automáticos de apoyo al análisis.
A lo largo del documento se respetará al máximo la estructura del script original, pero añadiendo comentarios explicativos para que pueda utilizarse directamente como material de laboratorio.
2 PREPROCESSING: Descriptiva Automàtica
2.1 Carreguem les llibreries
En primer lugar cargamos las librerías necesarias. Cada una aporta una funcionalidad distinta dentro del proceso de exploración automática.
# visdat: visualización estructural del dataset y de los valores perdidos# inspectdf: diagnóstico rápido de tipos, memoria, missing values y distribuciones# skimr: resumen descriptivo automático muy útil en una primera inspección# tidyverse: manipulación de datos con dplyr, pipes y utilidades de visualizaciónlist.of.packages <-c("visdat", "inspectdf", "skimr", "tidyverse", "dataReporter", "DataExplorer", "SmartEDA")# Detectamos qué paquetes no están instalados.new.packages <- list.of.packages[!(list.of.packages %in%installed.packages()[, "Package"])]# Instalamos los que falten.if (length(new.packages) >0) {install.packages(new.packages)}# Cargamos todas las librerías en memoria.lapply(list.of.packages, require, character.only =TRUE)
# Eliminamos objetos auxiliares del entorno.rm(list.of.packages, new.packages)
2.2 Carreguem les bases de dades
Cargamos la base de datos que vamos a analizar. En este caso se utiliza el fichero valentine_dataset.csv.
# Lectura del dataset desde la carpeta de trabajopath <-"https://ramia-lab.github.io/AdvancedModelling/material/01_AdvancedPreprocessing/laboratorio/valentine_dataset.csv"dades <-read.csv(path)
Antes de profundizar, puede ser útil inspeccionar rápidamente las primeras filas.
# Visualización inicial de las primeras observacioneshead(dades)
3 Paquete Skim
La librería skimr permite obtener un resumen automático muy completo del dataset. Es especialmente útil como primer diagnóstico global.
3.1 Podem visualitzar un descriptiu de les dades
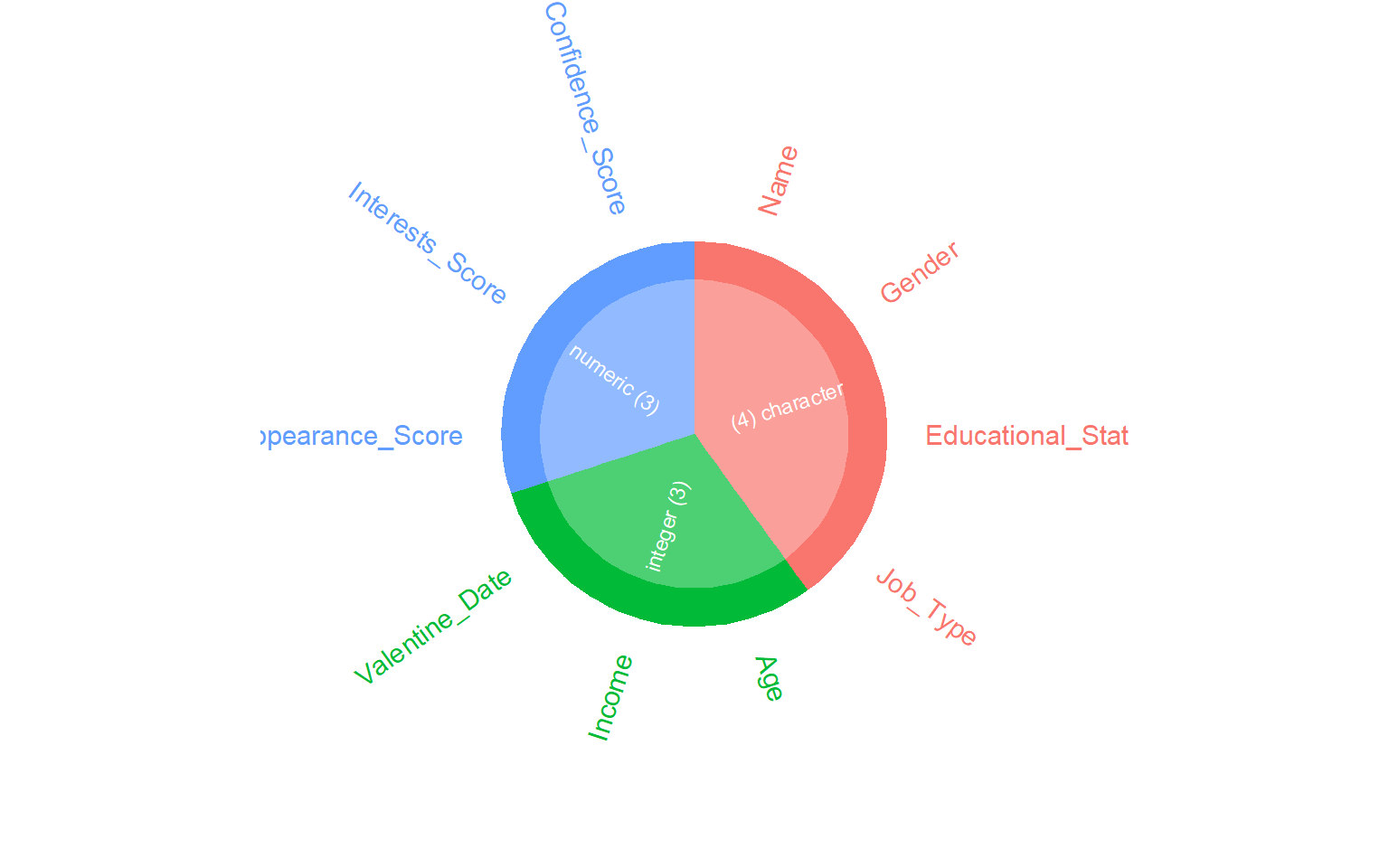
# Resumen general de todas las variables del datasetskim(dades)
Data summary
Name
dades
Number of rows
20000
Number of columns
10
_______________________
Column type frequency:
character
4
numeric
6
________________________
Group variables
None
Variable type: character
skim_variable
n_missing
complete_rate
min
max
empty
n_unique
whitespace
Name
0
1
6
27
0
17795
0
Gender
0
1
4
6
0
2
0
Educational_Status
0
1
3
11
0
4
0
Job_Type
0
1
8
13
0
2
0
Variable type: numeric
skim_variable
n_missing
complete_rate
mean
sd
p0
p25
p50
p75
p100
hist
Age
0
1
29.03
6.62
18.00
23.00
29.00
35.00
40.00
▇▆▇▆▇
Income
0
1
50051.03
17329.78
20004.00
35013.25
50230.00
65120.50
79998.00
▇▇▇▇▇
Appearance_Score
0
1
50.14
28.88
0.00
25.07
50.32
75.22
99.99
▇▇▇▇▇
Interests_Score
0
1
49.95
28.77
0.01
25.31
49.53
74.88
100.00
▇▇▇▇▇
Confidence_Score
0
1
49.91
28.98
0.01
24.81
49.96
74.95
100.00
▇▇▇▇▇
Valentine_Date
0
1
0.49
0.50
0.00
0.00
0.00
1.00
1.00
▇▁▁▁▇
Este resumen permite identificar de forma muy rápida:
número de observaciones,
tipo de variables,
número de valores perdidos,
estadísticos descriptivos básicos.
3.2 Visualitzem exclusivament les variables numèriques
# Extraemos únicamente el resumen de las variables numéricasskim(dades) %>%yank("numeric")
Variable type: numeric
skim_variable
n_missing
complete_rate
mean
sd
p0
p25
p50
p75
p100
hist
Age
0
1
29.03
6.62
18.00
23.00
29.00
35.00
40.00
▇▆▇▆▇
Income
0
1
50051.03
17329.78
20004.00
35013.25
50230.00
65120.50
79998.00
▇▇▇▇▇
Appearance_Score
0
1
50.14
28.88
0.00
25.07
50.32
75.22
99.99
▇▇▇▇▇
Interests_Score
0
1
49.95
28.77
0.01
25.31
49.53
74.88
100.00
▇▇▇▇▇
Confidence_Score
0
1
49.91
28.98
0.01
24.81
49.96
74.95
100.00
▇▇▇▇▇
Valentine_Date
0
1
0.49
0.50
0.00
0.00
0.00
1.00
1.00
▇▁▁▁▇
Aquí el alumnado puede fijarse especialmente en:
media,
desviación típica,
percentiles,
posibles asimetrías o rangos extremos.
3.3 Visualitzem exclusivament les variables categòriques
# Extraemos únicamente el resumen de las variables categóricas o de textoskim(dades) %>%yank("character")
Variable type: character
skim_variable
n_missing
complete_rate
min
max
empty
n_unique
whitespace
Name
0
1
6
27
0
17795
0
Gender
0
1
4
6
0
2
0
Educational_Status
0
1
3
11
0
4
0
Job_Type
0
1
8
13
0
2
0
En este caso interesa observar:
número de categorías distintas,
frecuencia de la categoría más repetida,
posibles problemas de codificación o cardinalidad elevada.
4 Paquete Visdat
La librería visdat está orientada a la visualización de la estructura de los datos y de los missing values.
4.1 Busquem per a variables numèriques o categòriques si hi ha NA’s
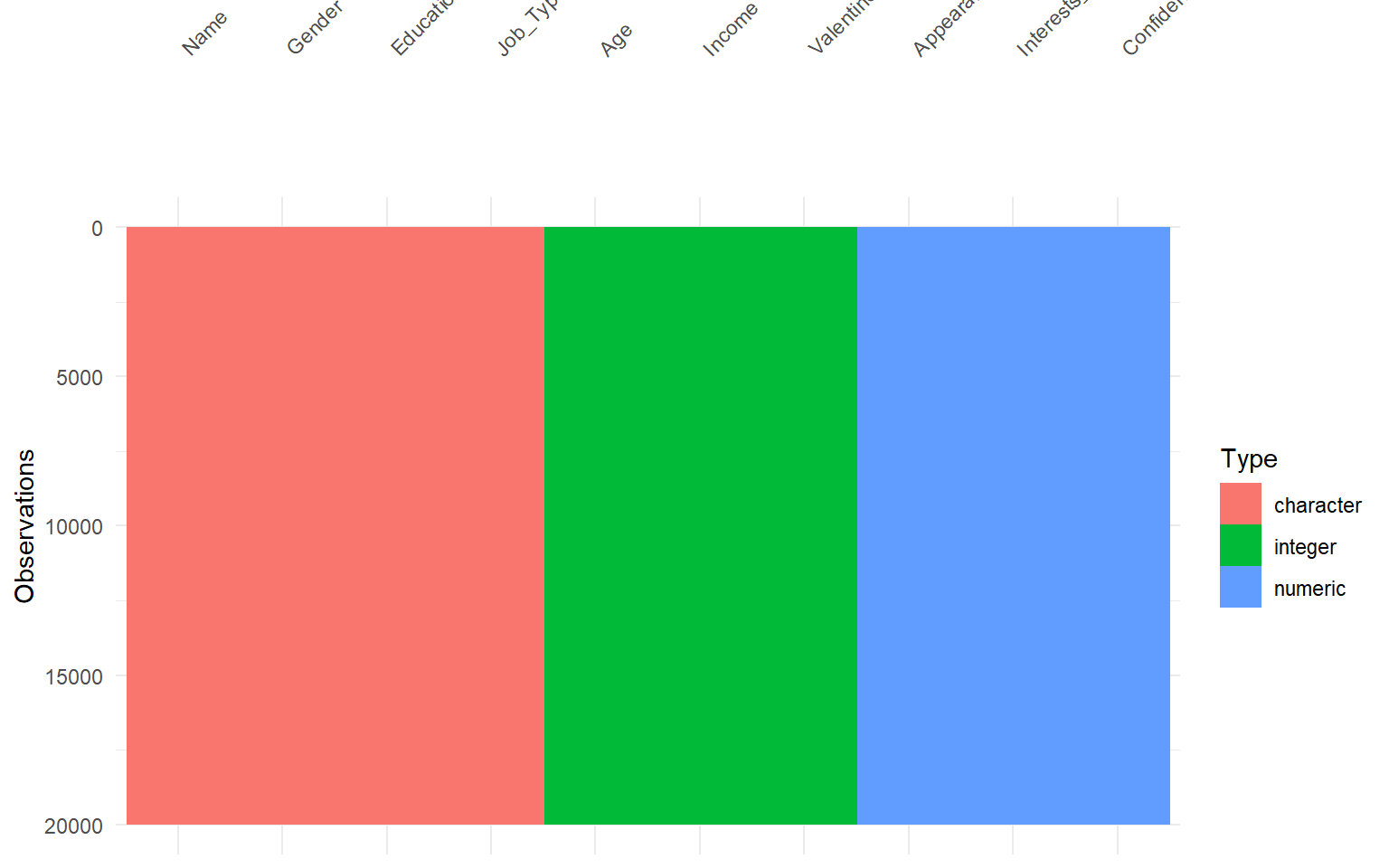
# Mapa general de tipos de dato y valores ausentesvis_dat(dades)
Este gráfico permite detectar visualmente:
qué tipo tiene cada variable,
si existen patrones de valores perdidos,
si hay mezclas inesperadas de tipos.
4.2 Visualitzem percentatges de NA’s en les variables
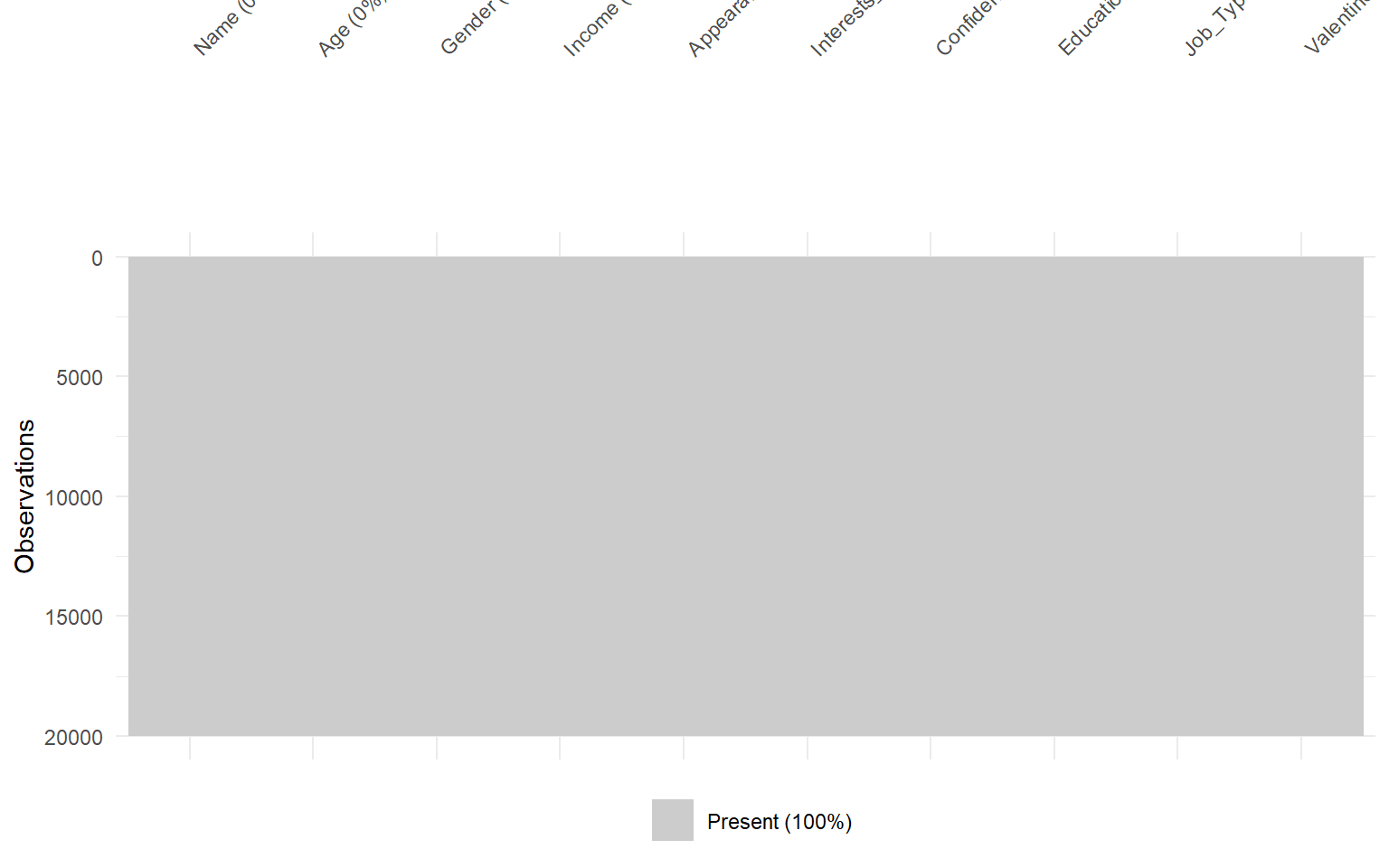
# Representación específica del porcentaje y localización de valores perdidosvis_miss(dades)
Pedagógicamente, este gráfico es muy útil para discutir si conviene:
imputar valores,
eliminar variables,
eliminar registros,
estudiar el mecanismo de missingness.
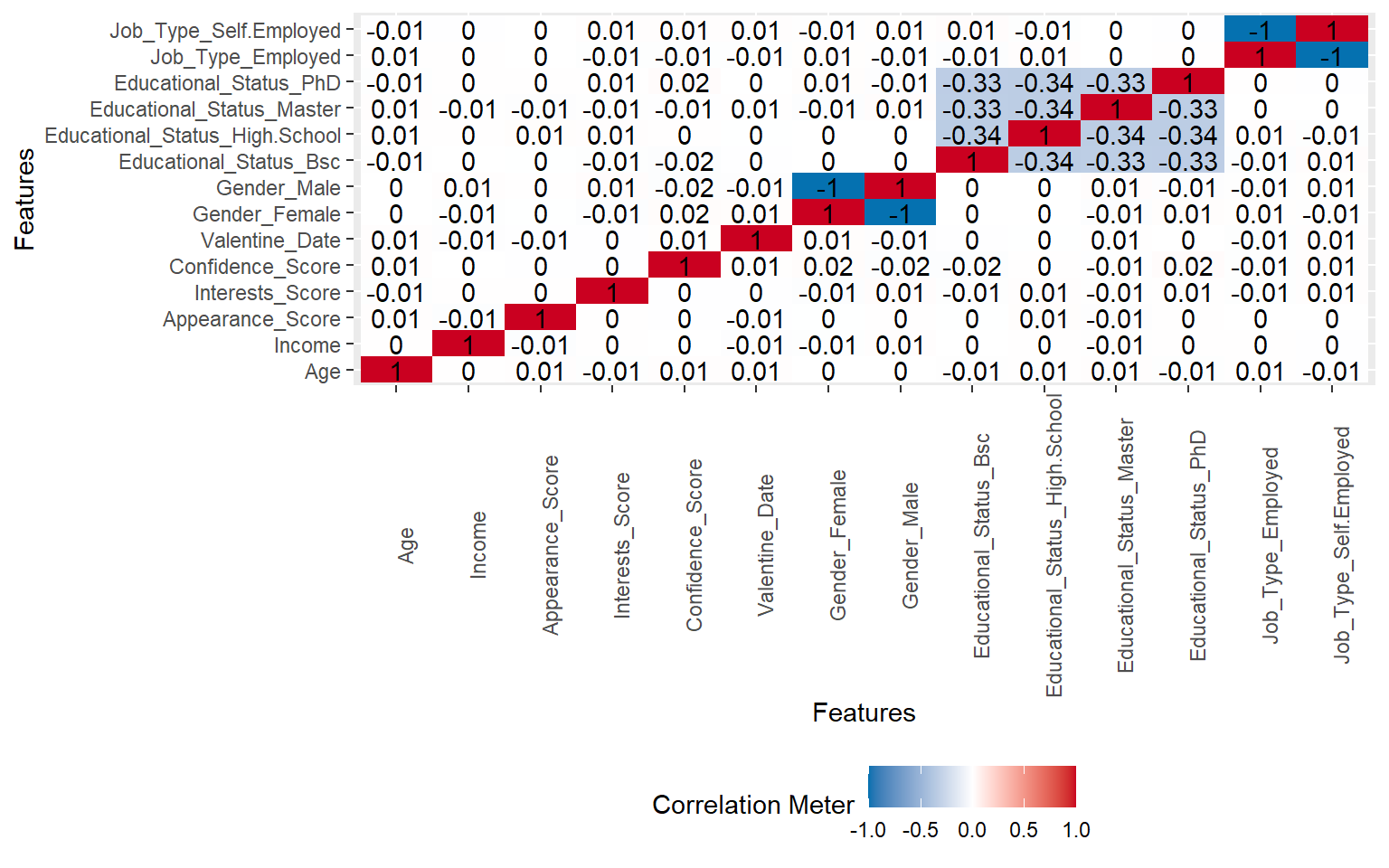
4.3 Generem la matriu de correlacions
Para generar la matriz de correlaciones necesitamos quedarnos solo con las variables numéricas.
# Seleccionamos las variables numéricas y representamos sus correlacionesdades %>%select(where(is.numeric)) %>%vis_cor()
Este paso es importante porque:
permite detectar relaciones lineales entre variables,
ayuda a identificar redundancia de información,
anticipa posibles problemas de multicolinealidad.
4.4 Podem visualitzar condicionants de les dades. En aquest cas, mirem si tenim més de 2 classes
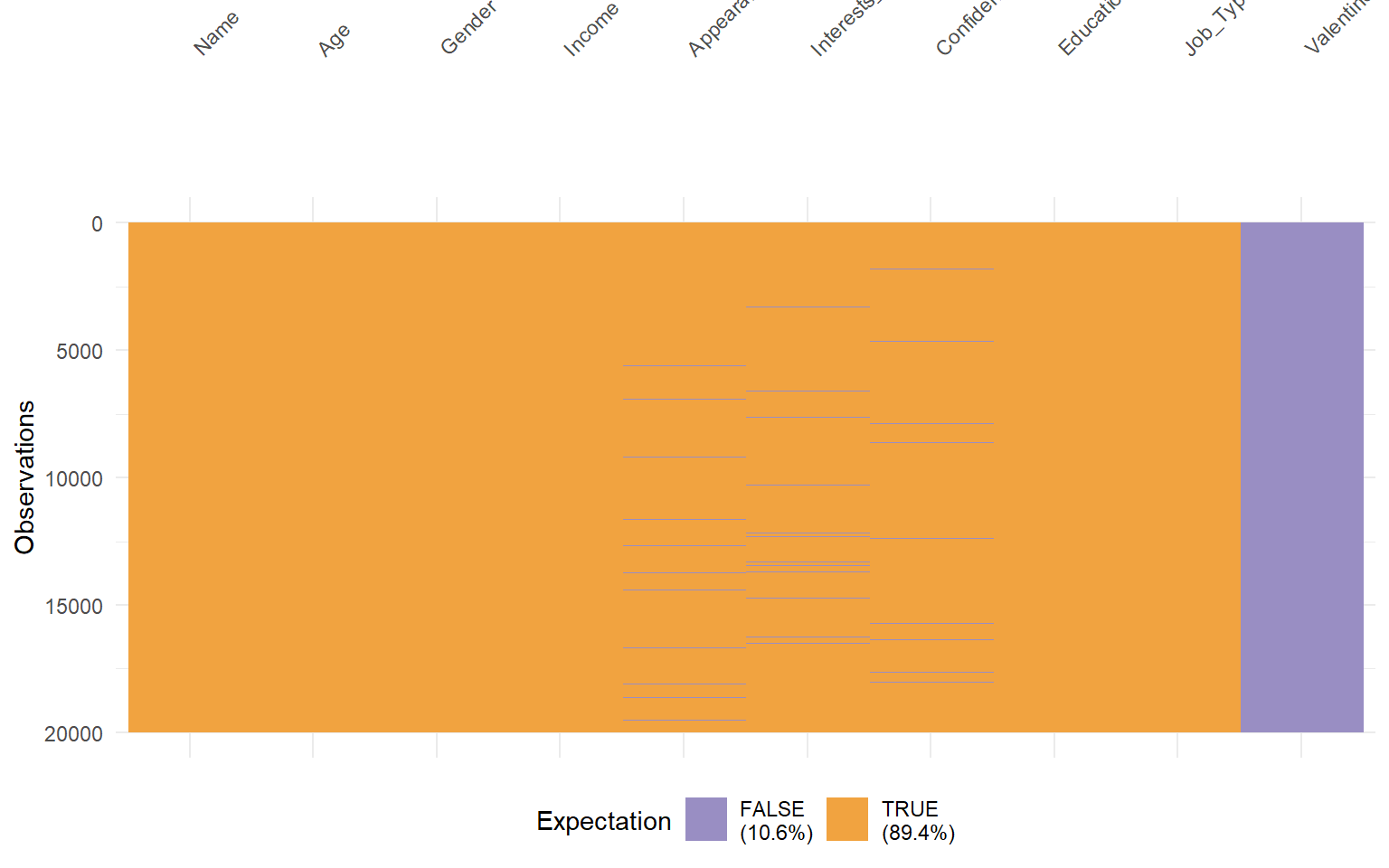
vis_expect() permite verificar si los datos cumplen una determinada condición lógica.
# Comprobamos visualmente qué valores cumplen la condición x > 2vis_expect(dades, ~ .x >2)
Este tipo de función resulta útil para construir reglas de validación y control de calidad del dato.
5 Inspectdf
La librería inspectdf ofrece un diagnóstico compacto y visual del dataset. Es muy adecuada para docencia porque transforma resúmenes complejos en gráficos interpretables.
5.1 Tipus de dades
# Inspección de los tipos de variables presentes en la base de datosinspect_types(dades) %>%show_plot()
Aquí se puede discutir con el alumnado:
si los tipos son coherentes,
si alguna variable debería recodificarse,
si hay variables de texto que realmente son categóricas.
5.2 Utilització de la memoria
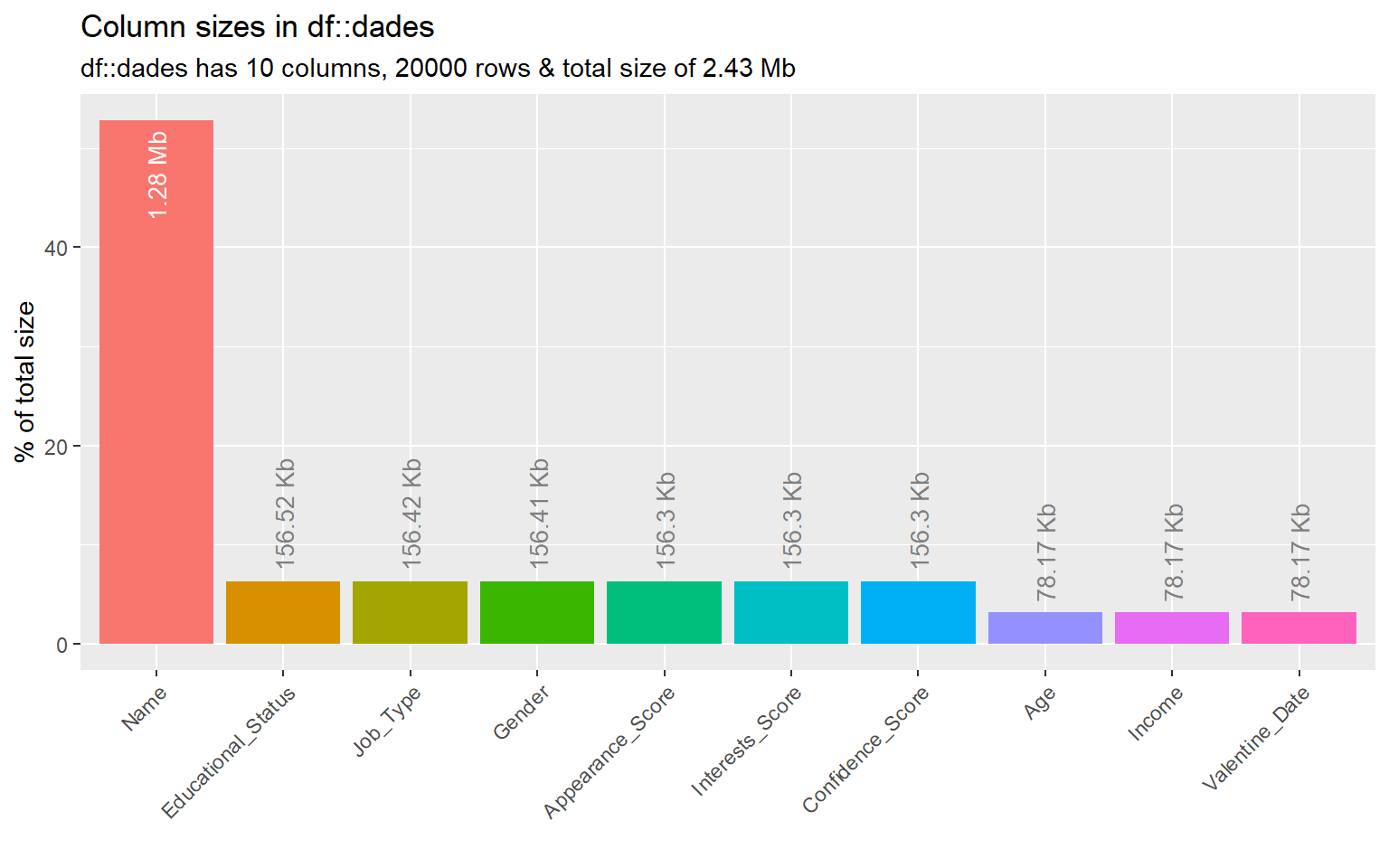
# Análisis del consumo de memoria por variableinspect_mem(dades) %>%show_plot()
Este análisis es especialmente interesante cuando se trabaja con bases de datos grandes, ya que ayuda a detectar variables costosas en almacenamiento.
5.3 Comprovem NA’s
Creamos una variable auxiliar (price_dummy) a partir de la renta (Income) para comparar patrones de missing values entre dos grupos.
# Creamos una variable categórica auxiliar según el nivel de ingresosdata_price_dummy <- dades %>%mutate(price_dummy =if_else(Income >10000, "High", "Low"))
# Comparamos los NA's entre el grupo de renta alta y el grupo de renta bajainspect_na(data_price_dummy %>%filter(price_dummy =="High"), data_price_dummy %>%filter(price_dummy =="Low")) %>%show_plot()
Esta comparación permite introducir una idea importante:
los valores ausentes no siempre se distribuyen de forma homogénea entre subgrupos de la población.
5.4 Comprovem la distribució de les variables
# Resumen visual de la distribución de variables numéricasinspect_num(dades) %>%show_plot()
Este gráfico ayuda a revisar:
dispersión,
asimetría,
presencia de valores extremos,
comportamiento global de las variables cuantitativas.
5.5 Check categorical variable distribution
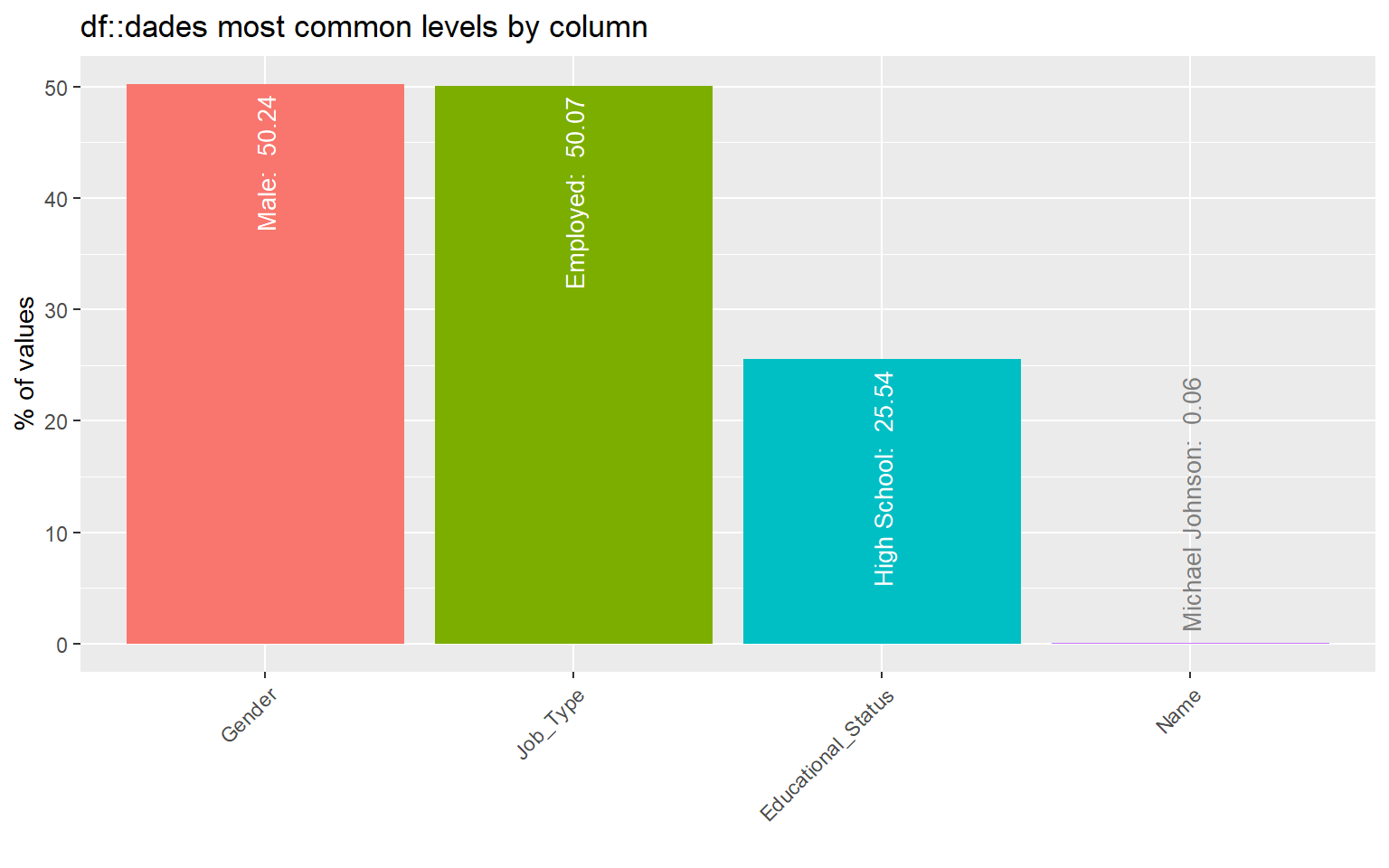
# Estudio del desbalance o distribución de las variables categóricasinspect_imb(dades) %>%show_plot()
Esto resulta especialmente útil para:
detectar clases muy desbalanceadas,
preparar problemas de clasificación,
valorar si una categoría tiene muy poca representación.
5.6 Check two categorical
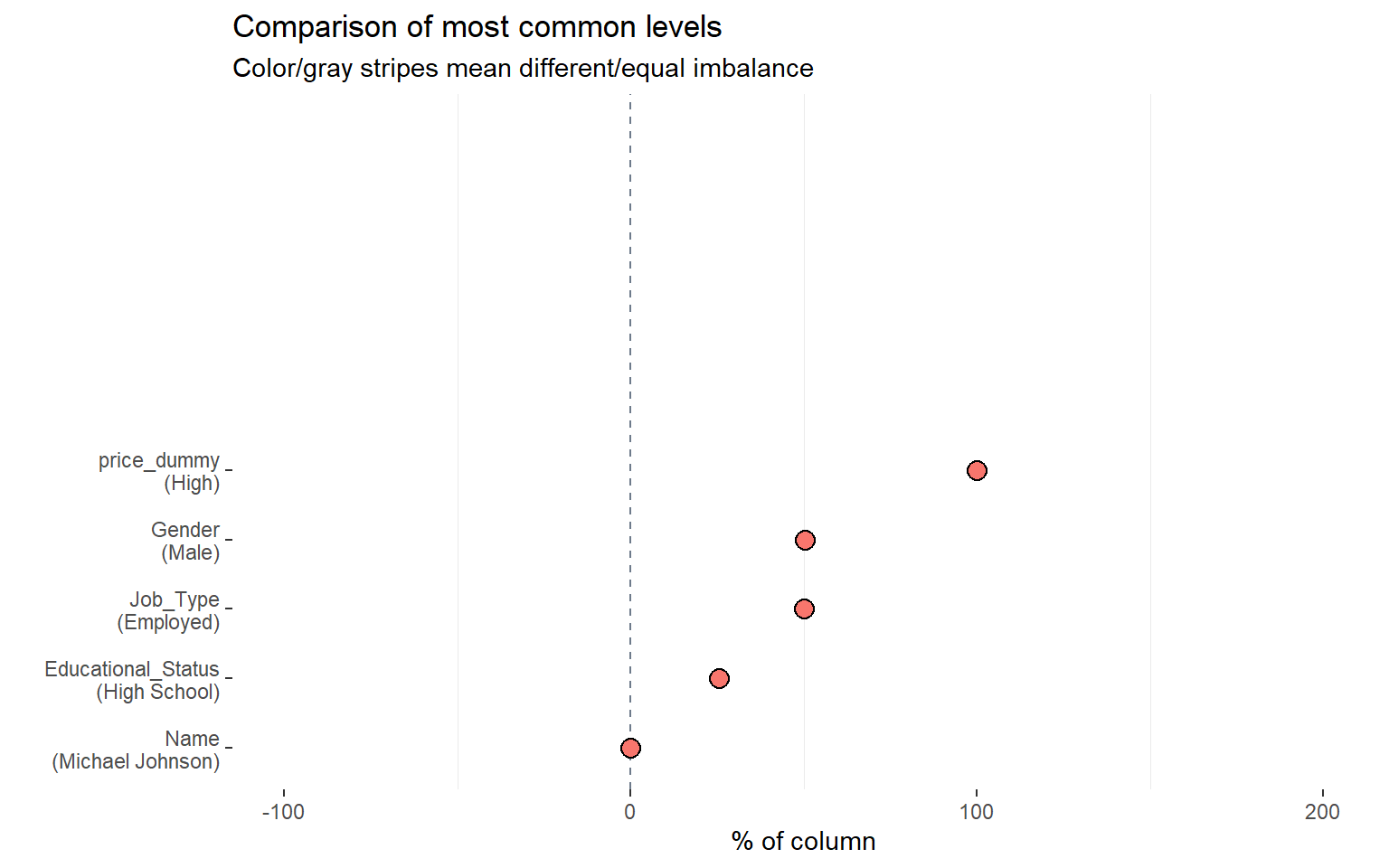
Comparamos de nuevo dos subconjuntos del dataset definidos por la variable price_dummy.
# Comparación del desbalance categórico entre dos subgruposinspect_imb(data_price_dummy %>%filter(price_dummy =="High"), data_price_dummy %>%filter(price_dummy =="Low")) %>%show_plot() +theme(legend.position ="none")
En términos docentes, este paso permite mostrar que la composición categórica puede variar mucho entre grupos.
5.7 Similar to inspect_imb, but for all levels
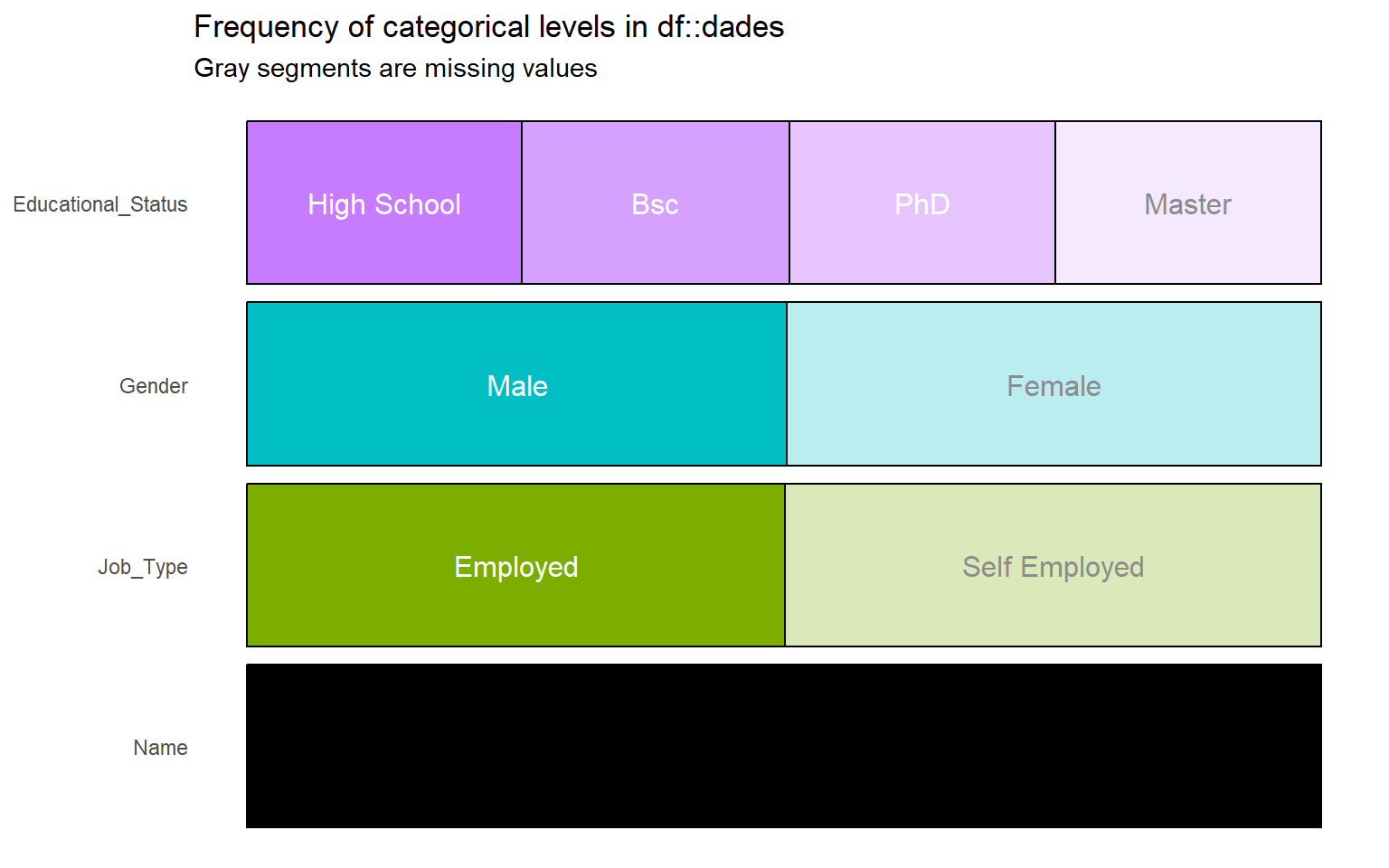
# Visualización completa de todas las categorías presentes en cada variable cualitativainspect_cat(dades) %>%show_plot()
Esto permite estudiar con más detalle la frecuencia de cada nivel categórico.
5.8 Correlacions
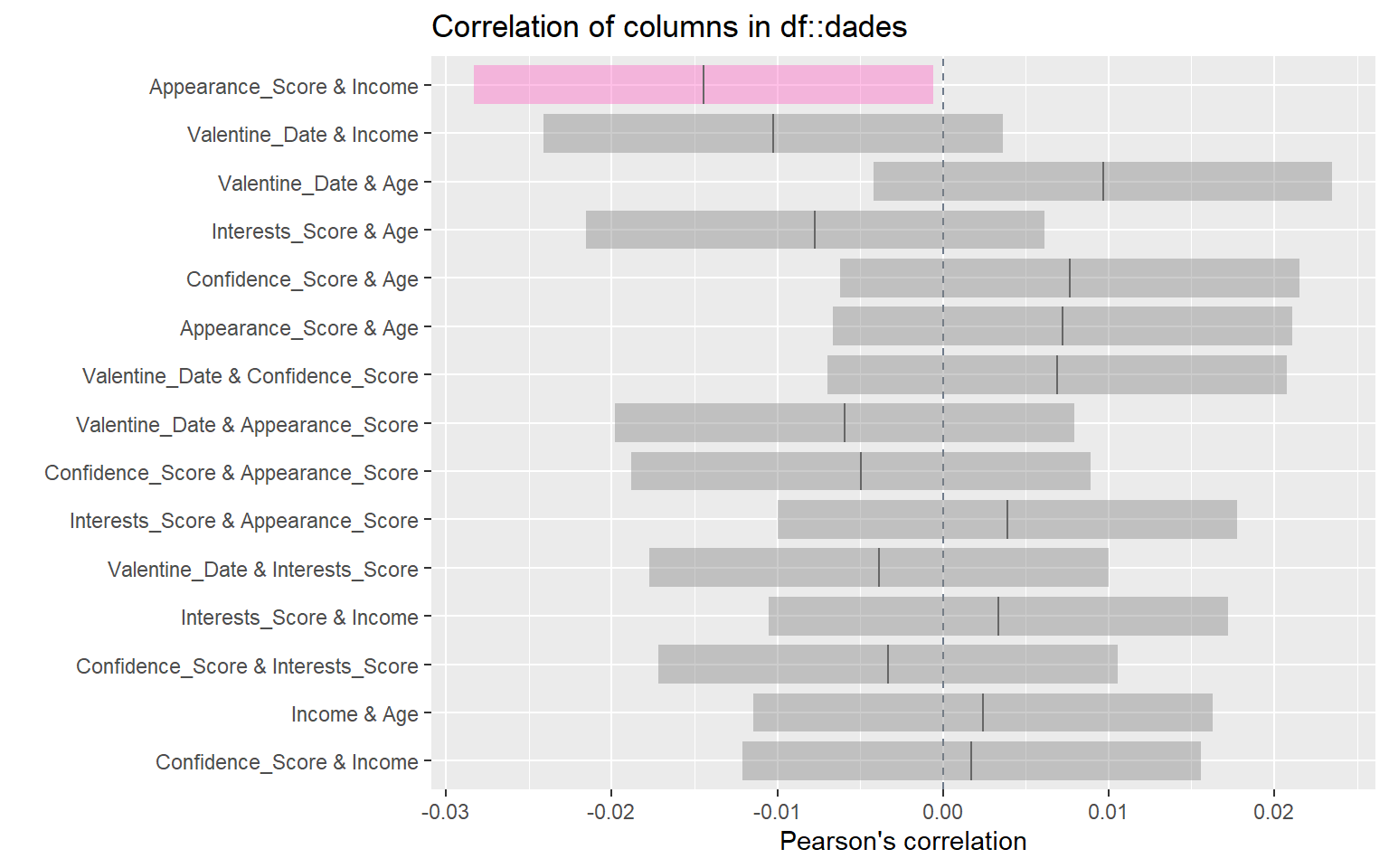
# Gráfico resumido de correlaciones entre variables numéricasinspect_cor(dades) %>%show_plot()
De nuevo, este análisis refuerza la importancia de estudiar relaciones entre variables antes de pasar a una fase de modelización.
6 dataReporter (antiguo dataMaid)
La librería dataReporter permite generar documentación automática del dataset, muy útil cuando se quiere dejar trazabilidad del análisis.
6.1 Generació d’un informe automàtic
# Generamos un informe HTML automático con información descriptiva del datasetdataReporter::makeDataReport( dades,output ="html",file ="report.Rmd")
6.2 Generació d’un codebook
# Generamos un codebook o diccionario automático del conjunto de datosdataReporter::makeCodebook(data = dades,file ="codebook.Rmd")
Observación docente: en el script original aparecían rutas absolutas del sistema local.
Aquí se han sustituido por rutas relativas para que el material sea portable y reutilizable en clase.
7 DataExplorer
DataExplorer es una de las librerías más prácticas para realizar una exploración rápida y visual del dataset.
7.1 Estructura general del dataset
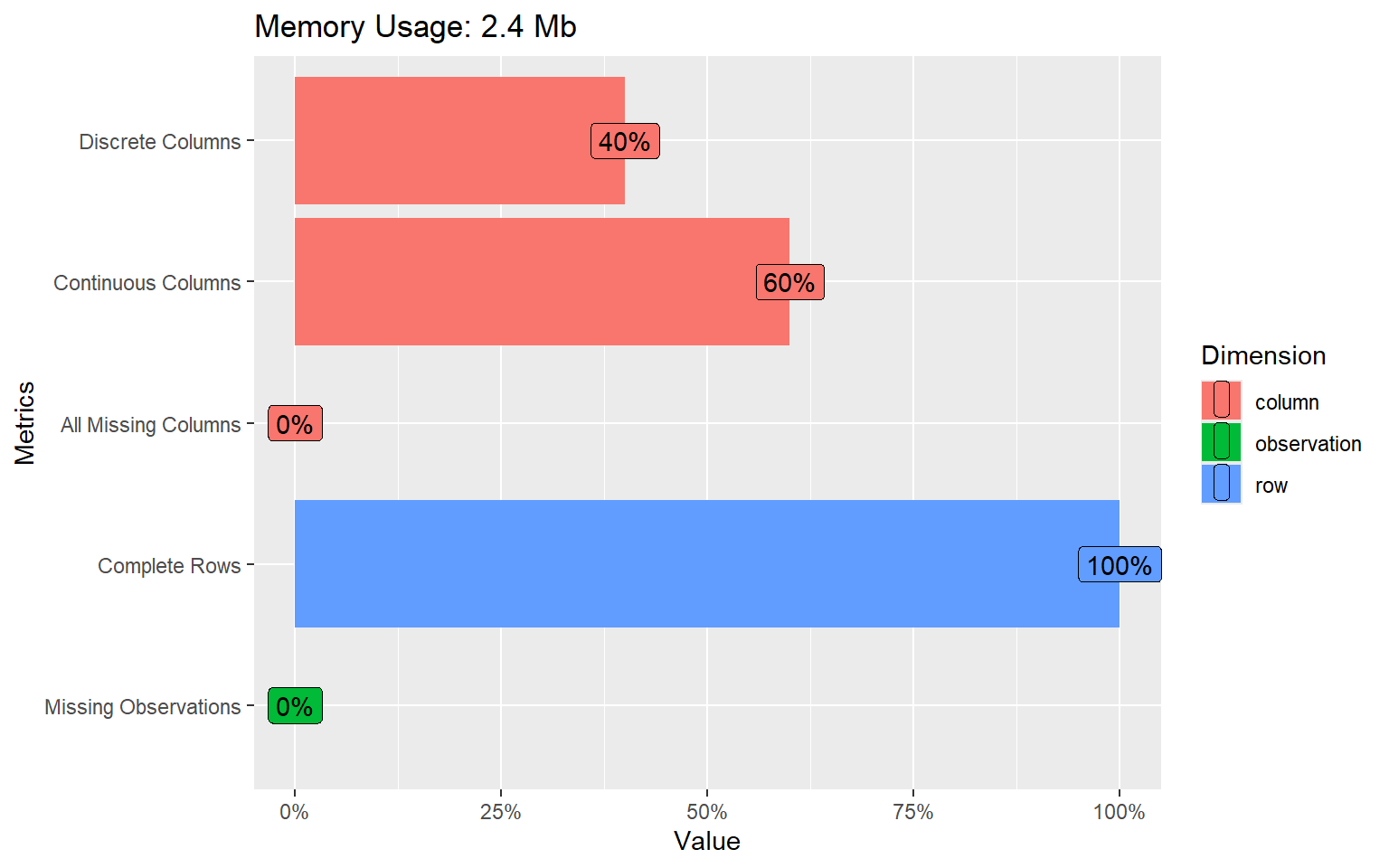
# Representación de la estructura del datasetplot_str(dades)# Resumen introductorio del conjunto de datosintroduce(dades)
Estos comandos son útiles para una primera fotografía global de la base de datos.
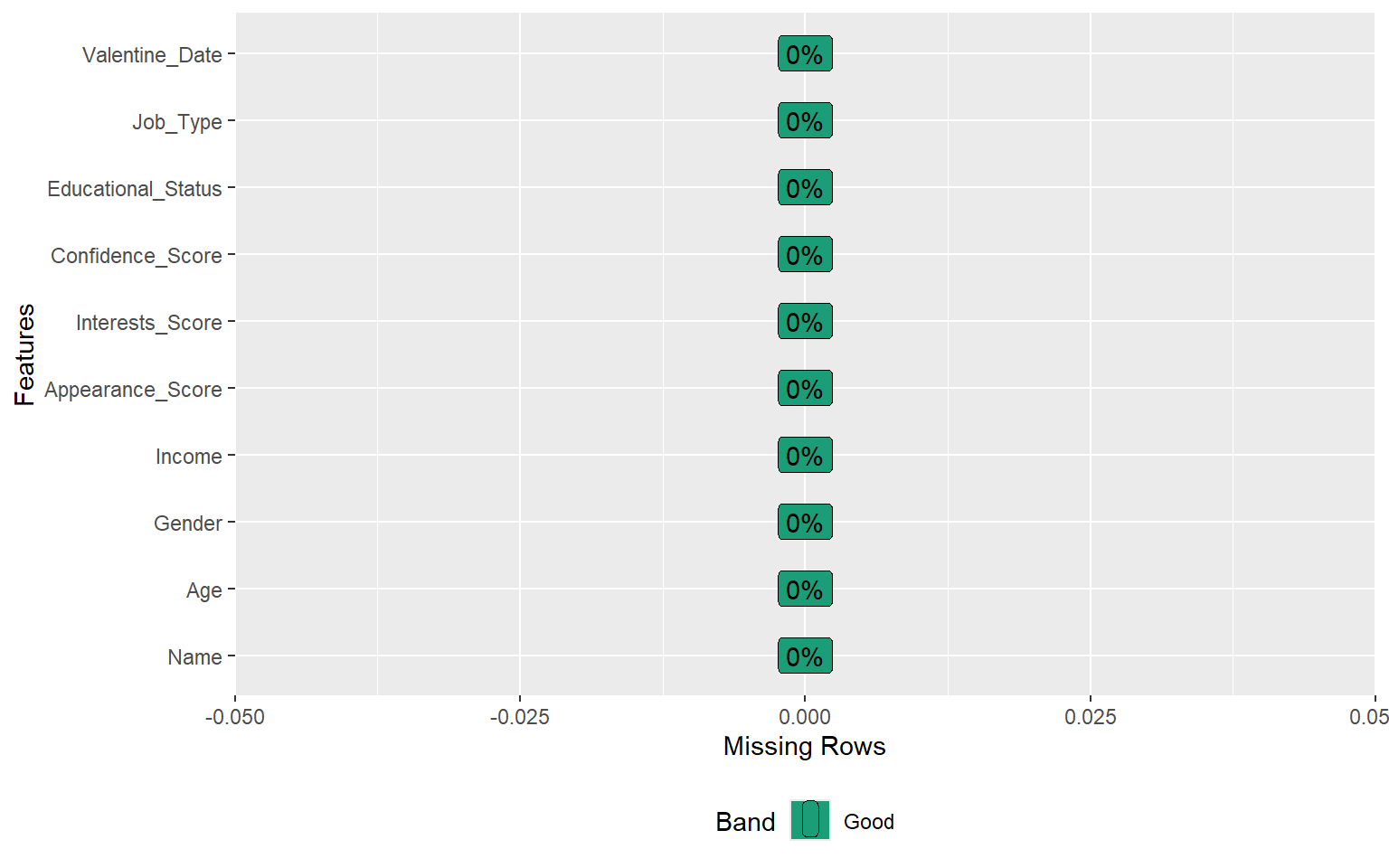
7.2 Missing values
# Visualización de valores ausentesplot_missing(dades)
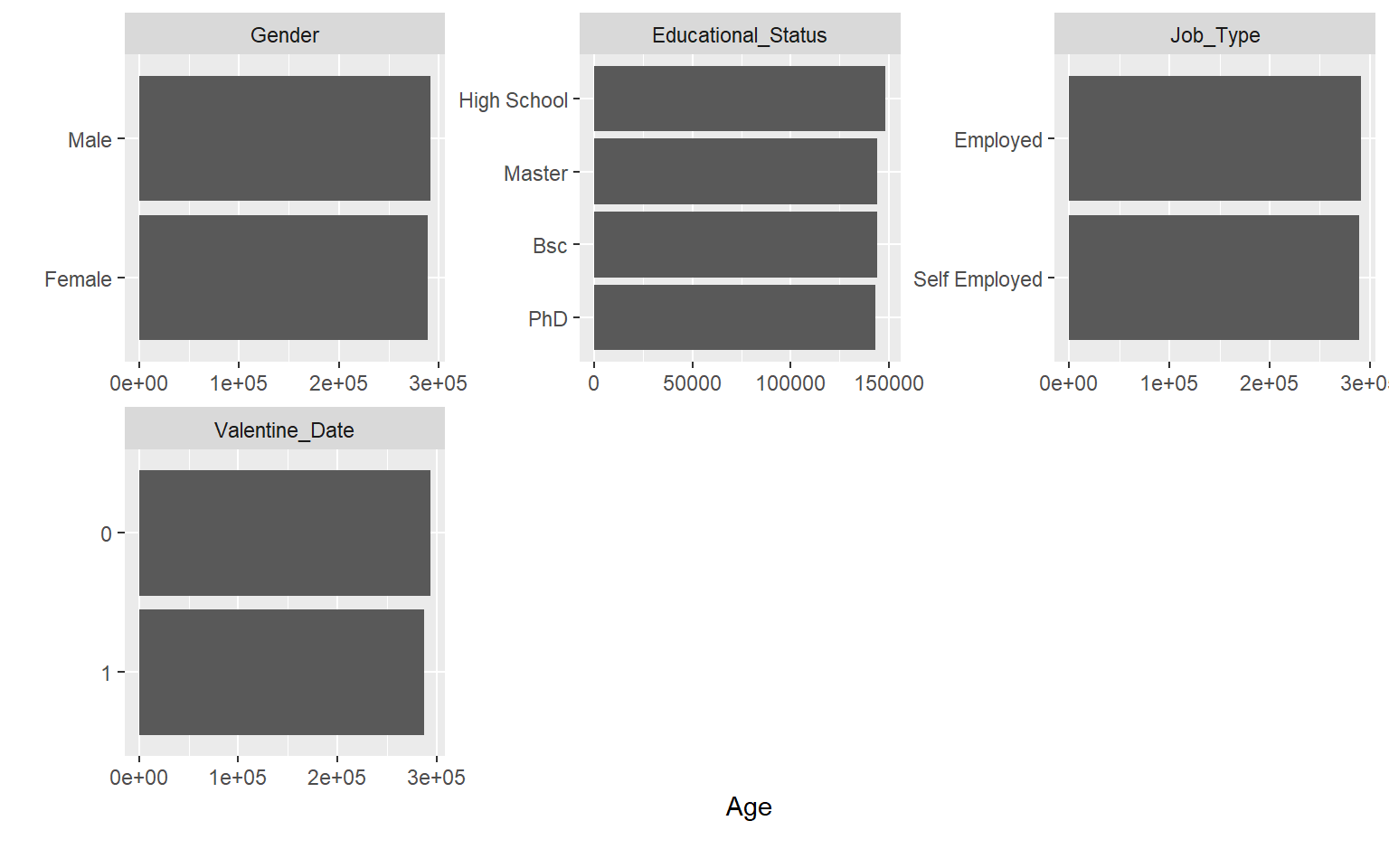
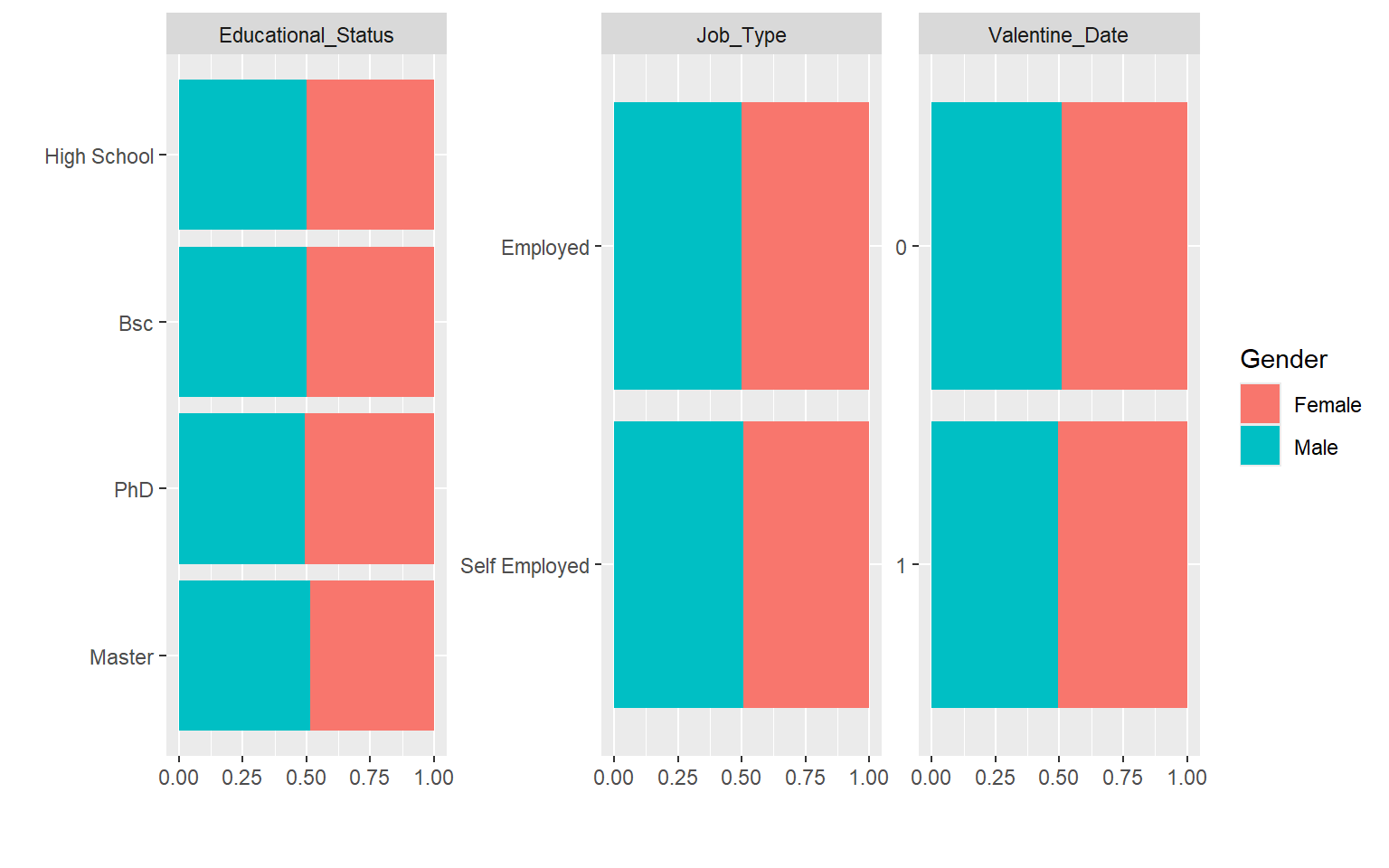
7.3 Variables categóricas
# Diagramas de barras para variables categóricasplot_bar(dades)
# Barras condicionadas por la variable Ageplot_bar(dades, with ="Age")
# Barras agrupadas por la variable Genderplot_bar(dades, by ="Gender")
Aquí se puede trabajar en clase:
interpretación de frecuencias,
relación entre variables categóricas,
patrones segmentados por grupo.
7.4 Variables numéricas
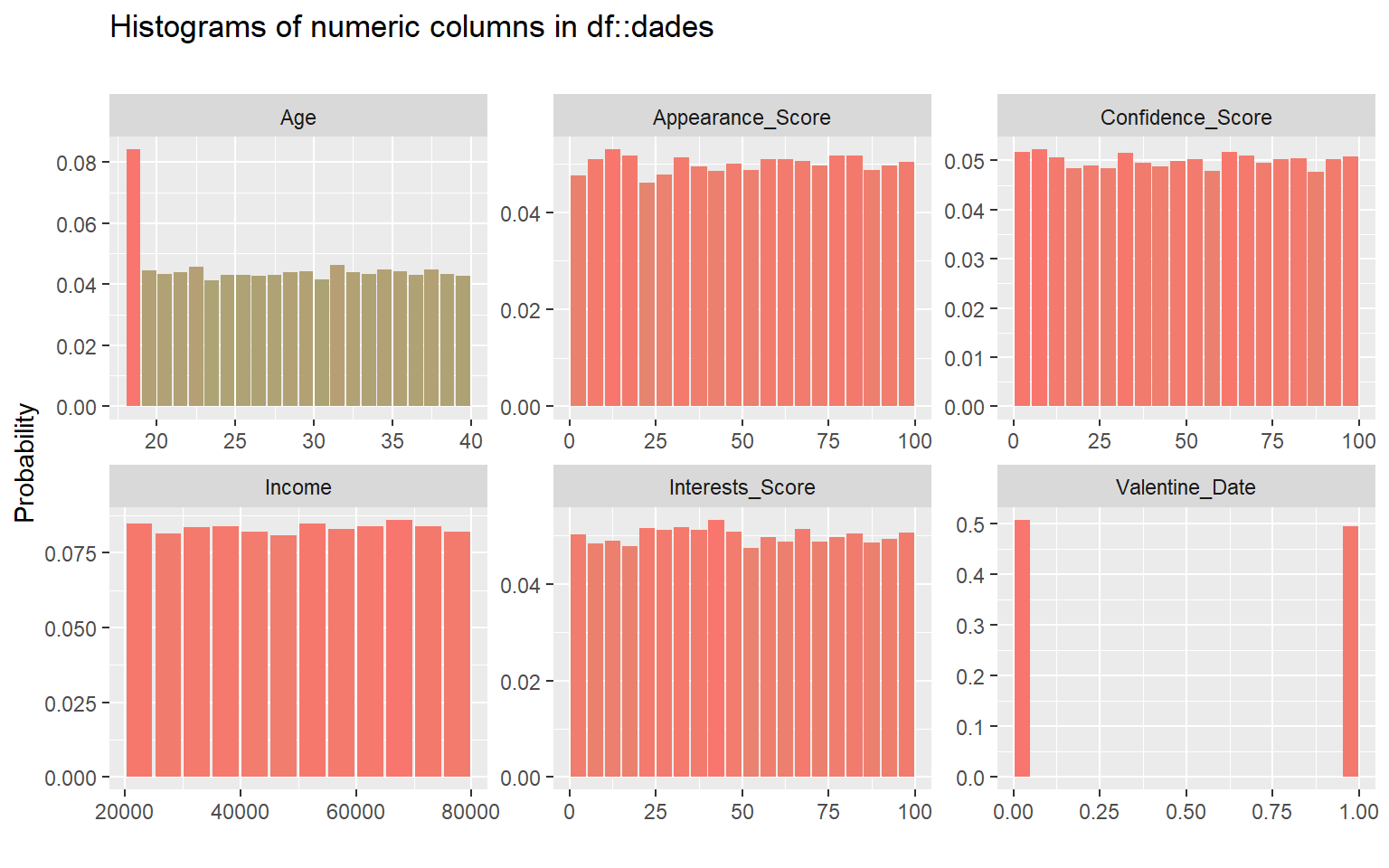
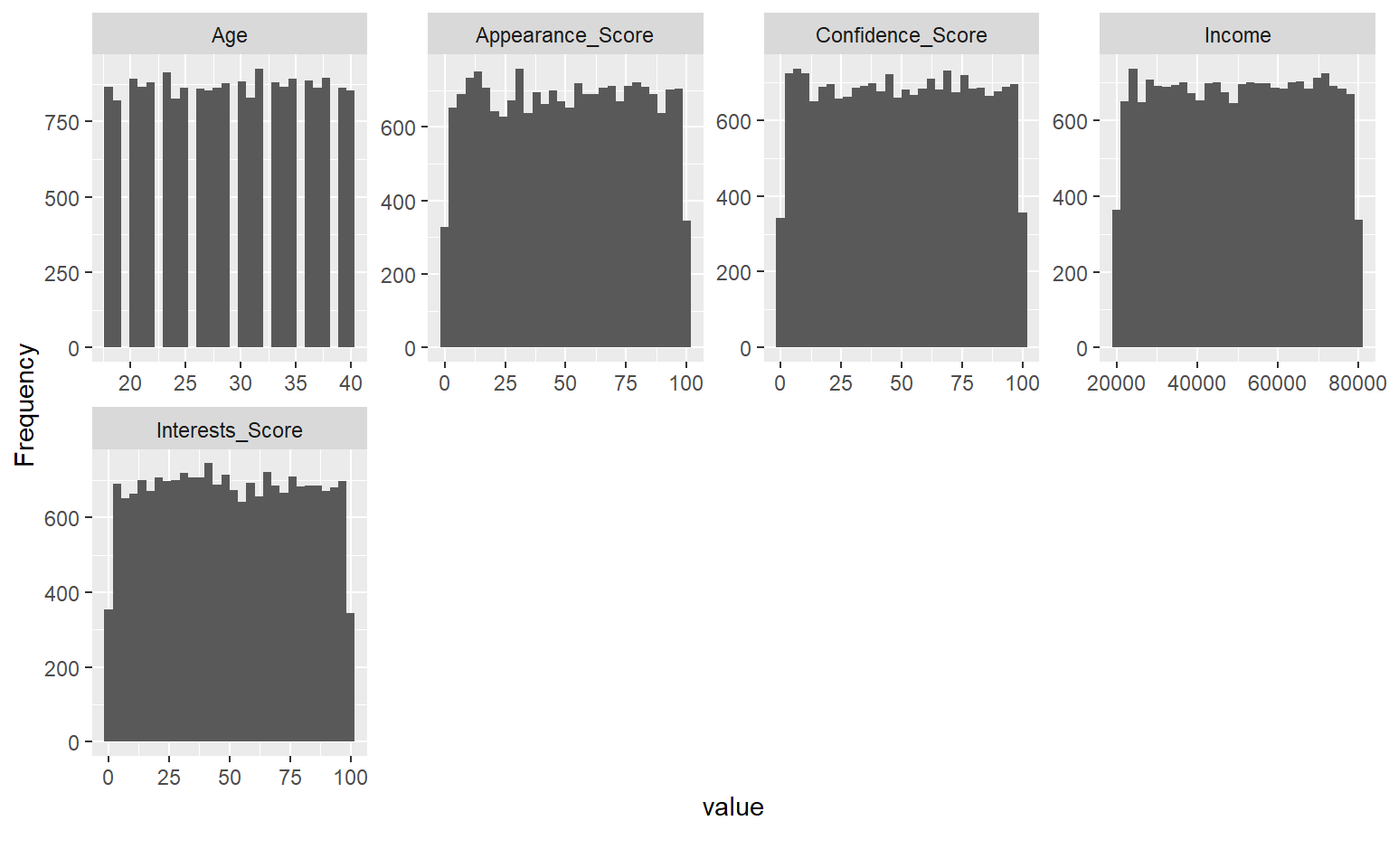
# Histogramas automáticos de las variables numéricasplot_histogram(dades)
7.5 Correlacions
# Mapa de correlaciones eliminando previamente los NA'splot_correlation(na.omit(dades), maxcat =5L)
Se utiliza na.omit() porque muchas funciones de correlación requieren una matriz sin valores ausentes.
8 SmartEDA
La librería SmartEDA combina resúmenes estadísticos con visualizaciones y tablas interpretables.
Es especialmente útil cuando se quiere una exploración semiautomática más detallada.
8.1 Overview of the data
# Vista general del datasetExpData(data = dades, type =1)
8.2 Structure of the data
# Estructura del dataset: tipos, dimensiones y composiciónExpData(data = dades, type =2)
9.2 Summary statistics by – overall with correlation
# Estadísticos descriptivos incorporando una variable de agrupaciónExpNumStat( dades,by ="A",gp ="Age",Qnt =seq(0, 1, 0.1),MesofShape =1,Outlier =TRUE,round =2)
Aunque Age sea numérica, aquí se está utilizando como referencia de agrupación dentro del análisis.
9.3 Summary statistics by – category
# Estadísticos numéricos segmentados por la categoría GenderExpNumStat( dades,by ="GA",gp ="Gender",Qnt =seq(0, 1, 0.1),MesofShape =2,Outlier =TRUE,round =2)
Esto permite comparar el comportamiento de las variables numéricas entre grupos categóricos.
10 Graphical representation of all numeric features
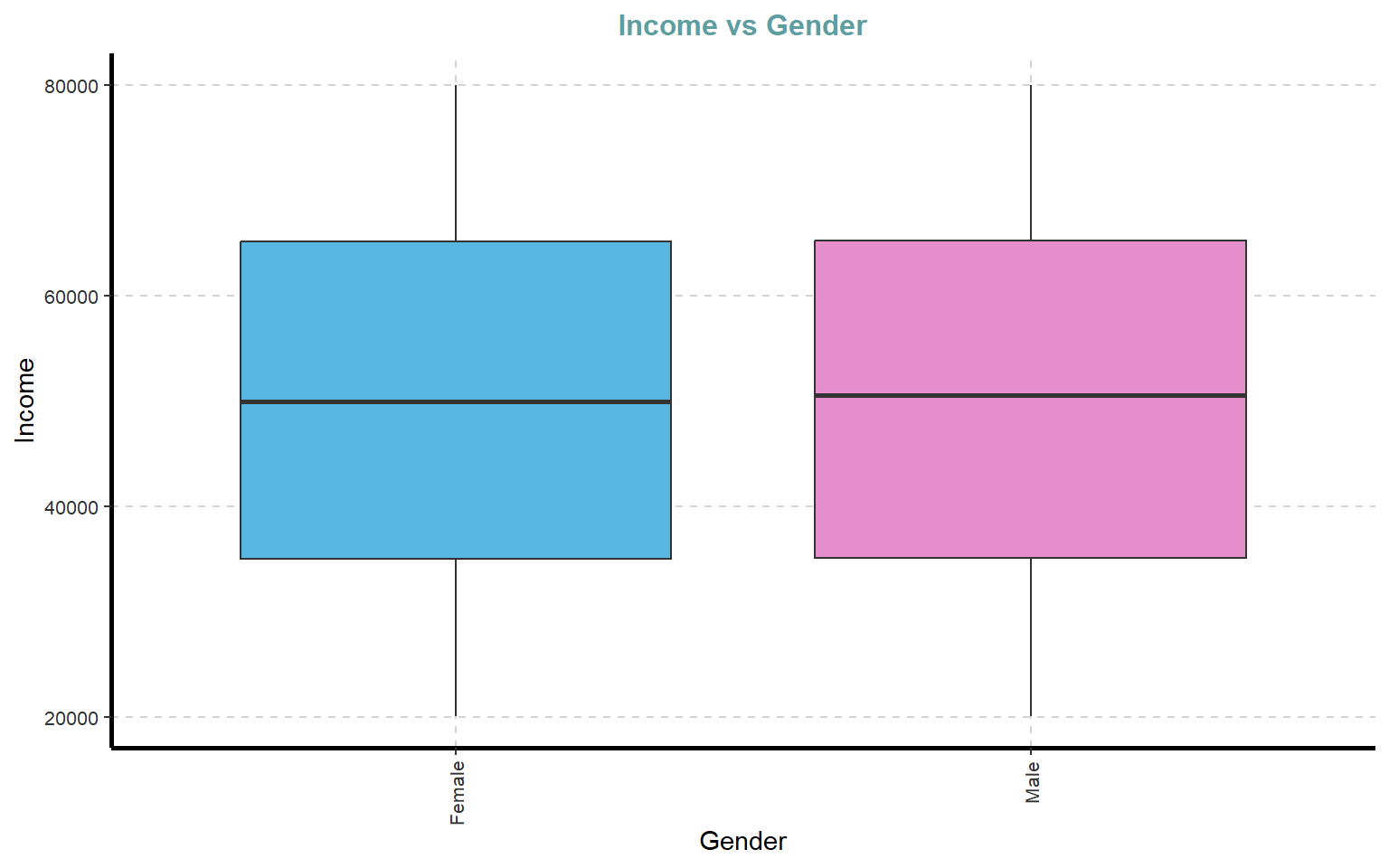
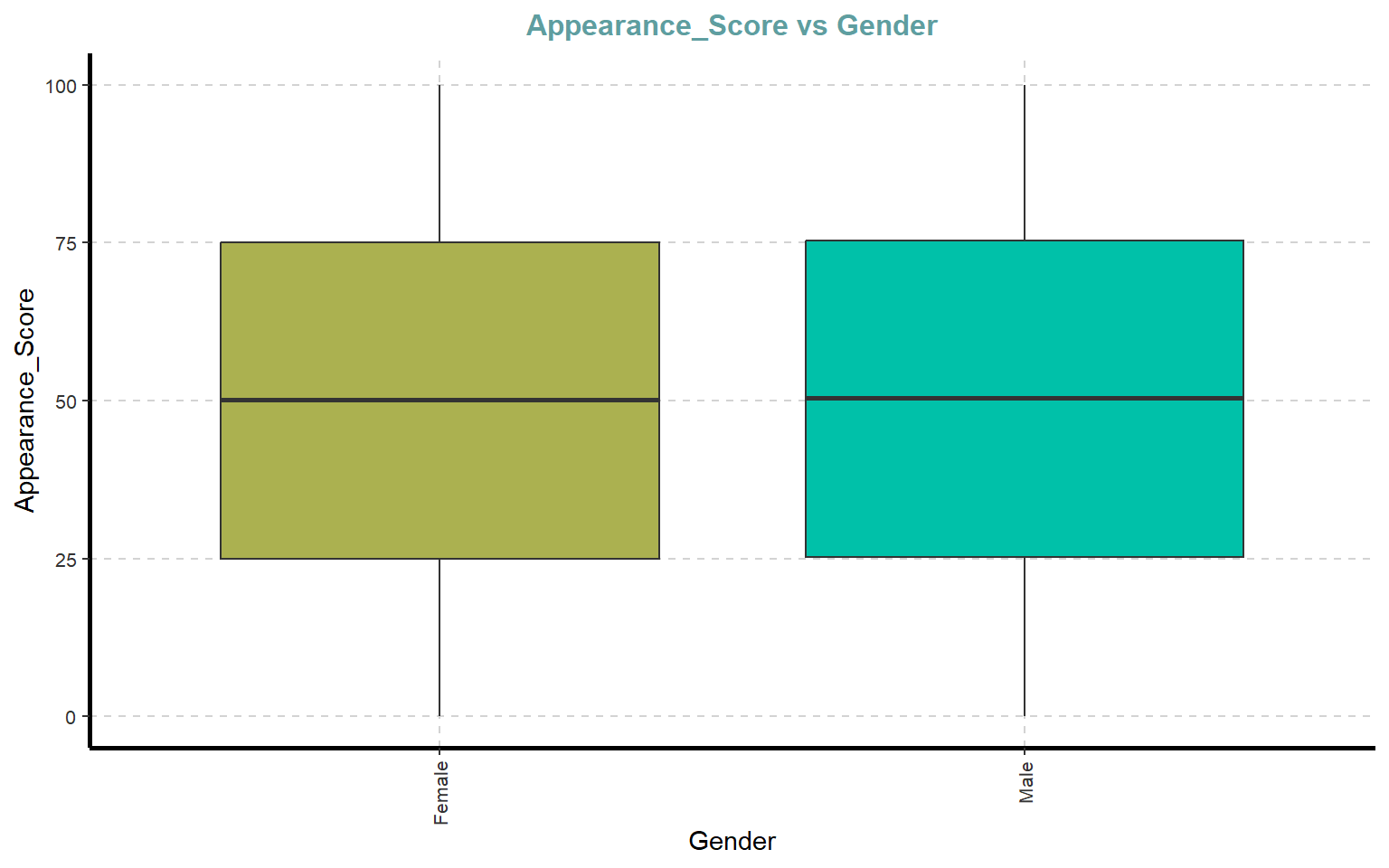
10.1 Generate Boxplot by category
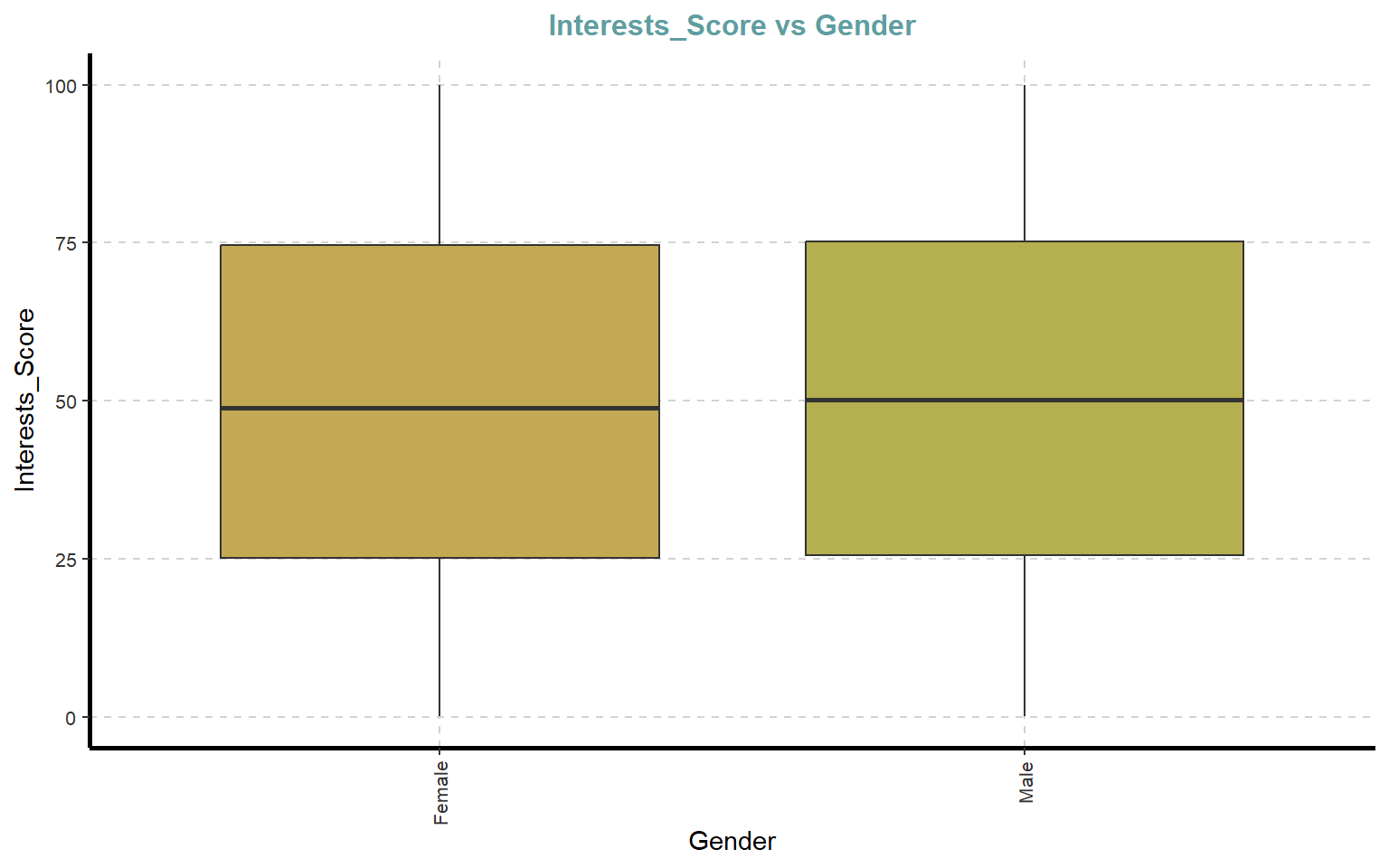
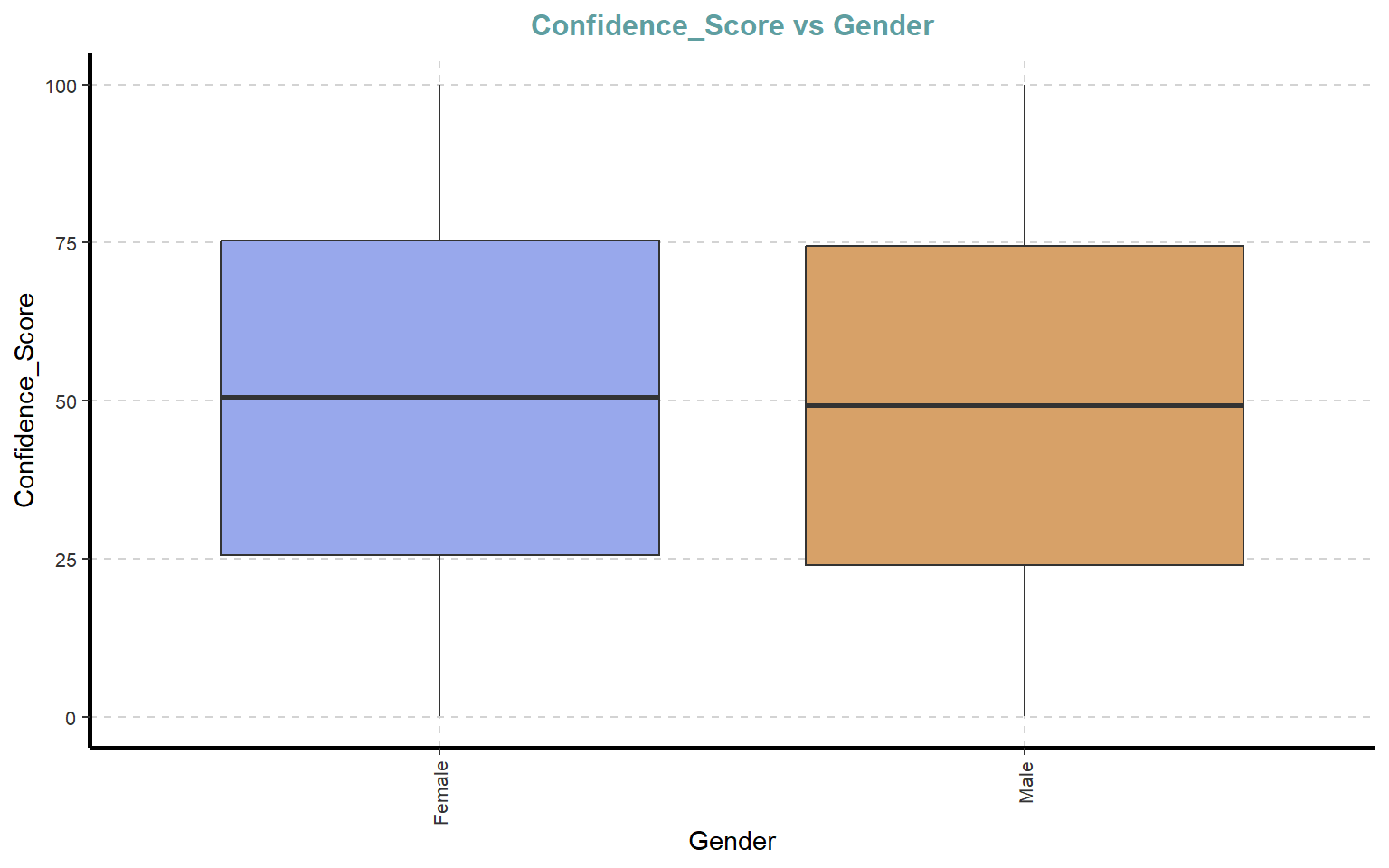
# Boxplots de variables numéricas segmentadas por GenderExpNumViz(dades, target ="Gender", type =2, nlim =25)
[[1]]
[[2]]
[[3]]
[[4]]
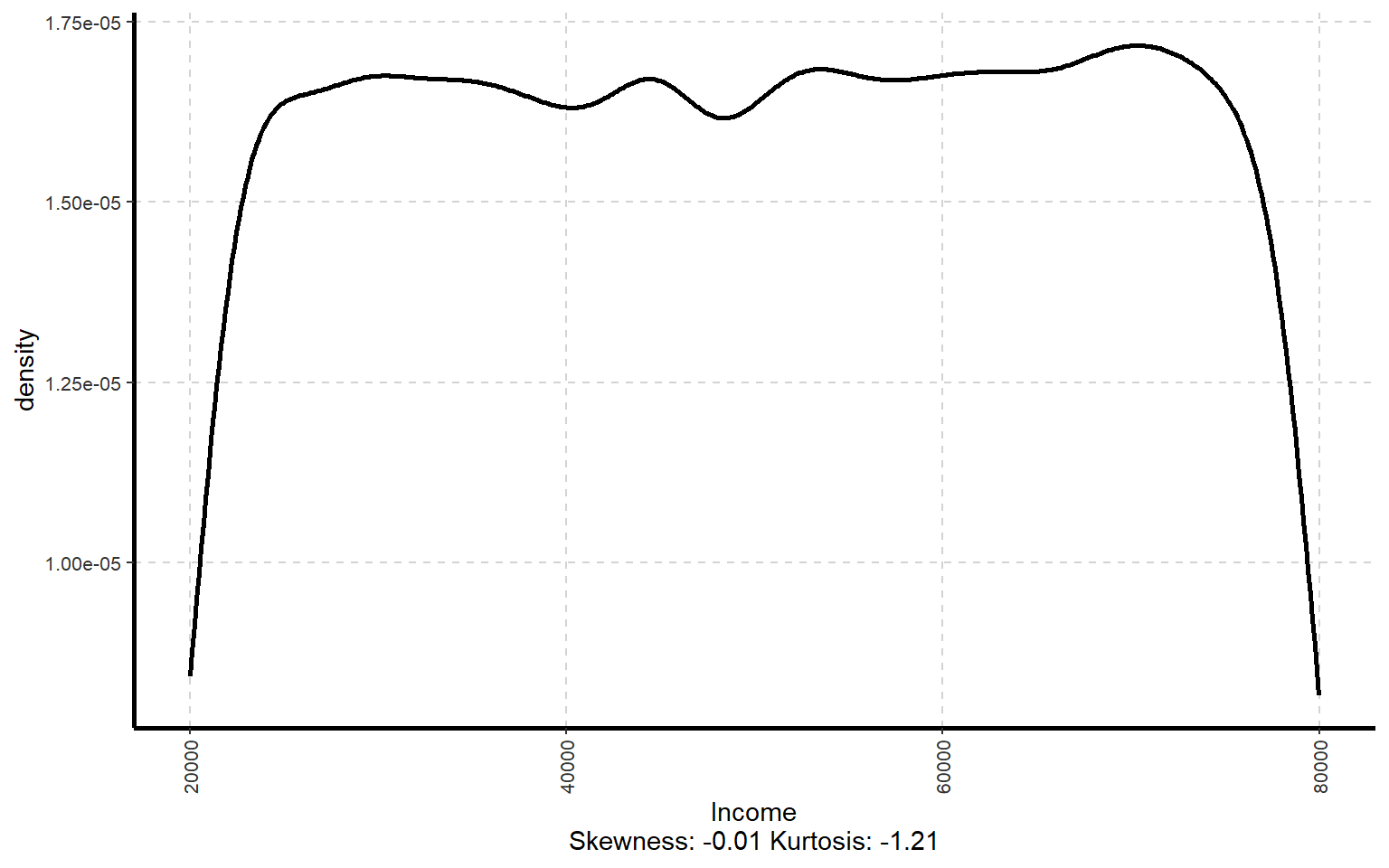
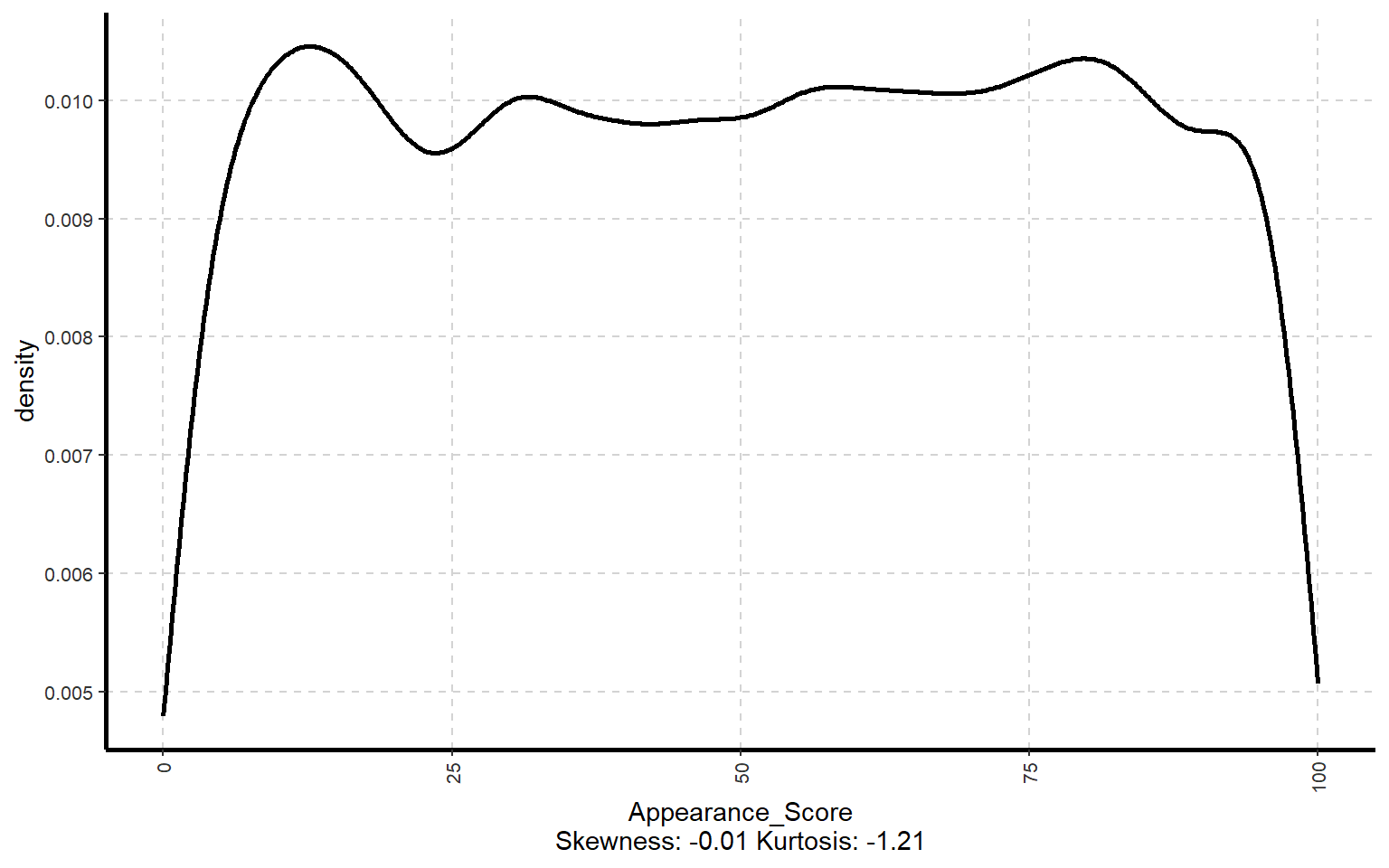
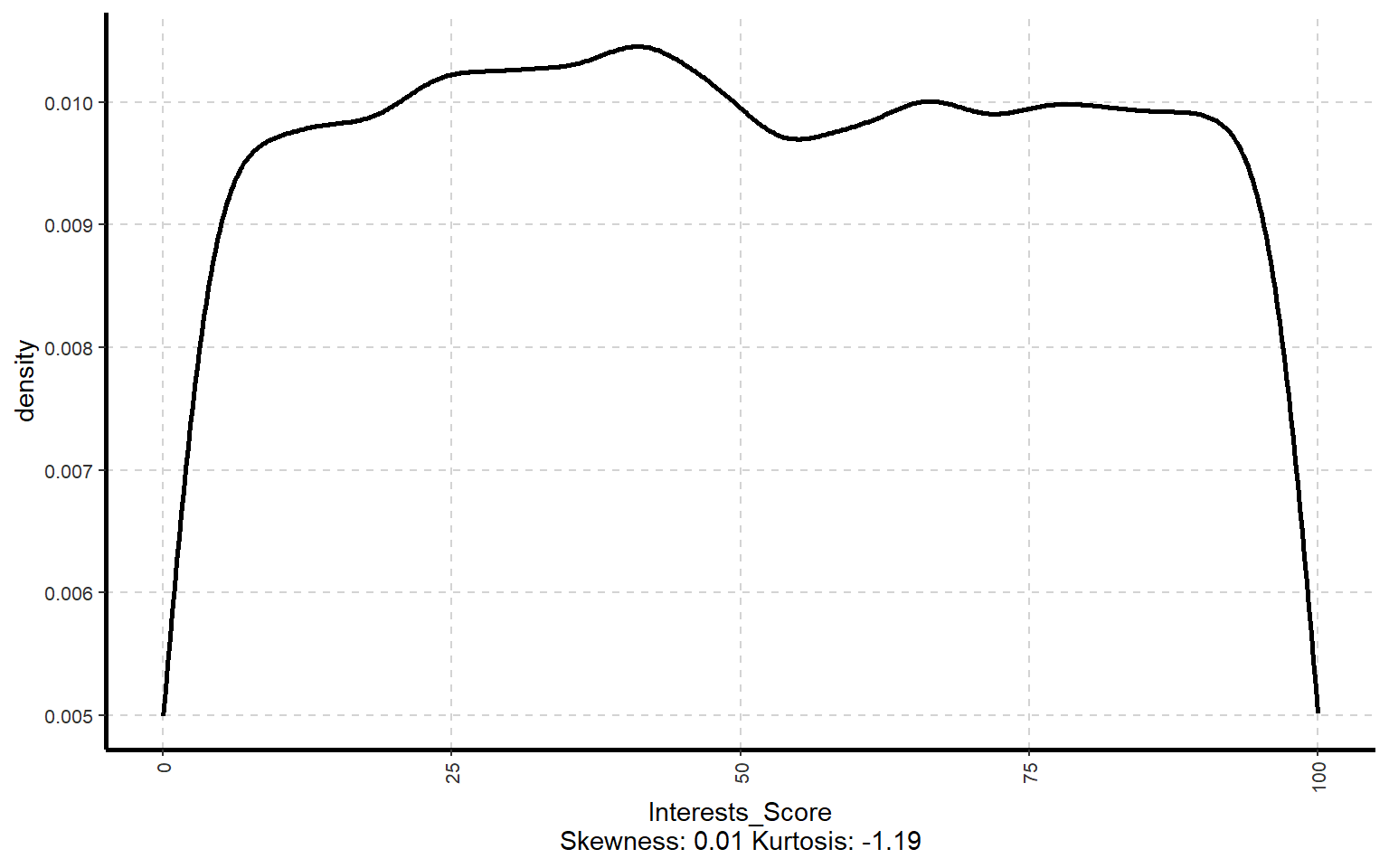
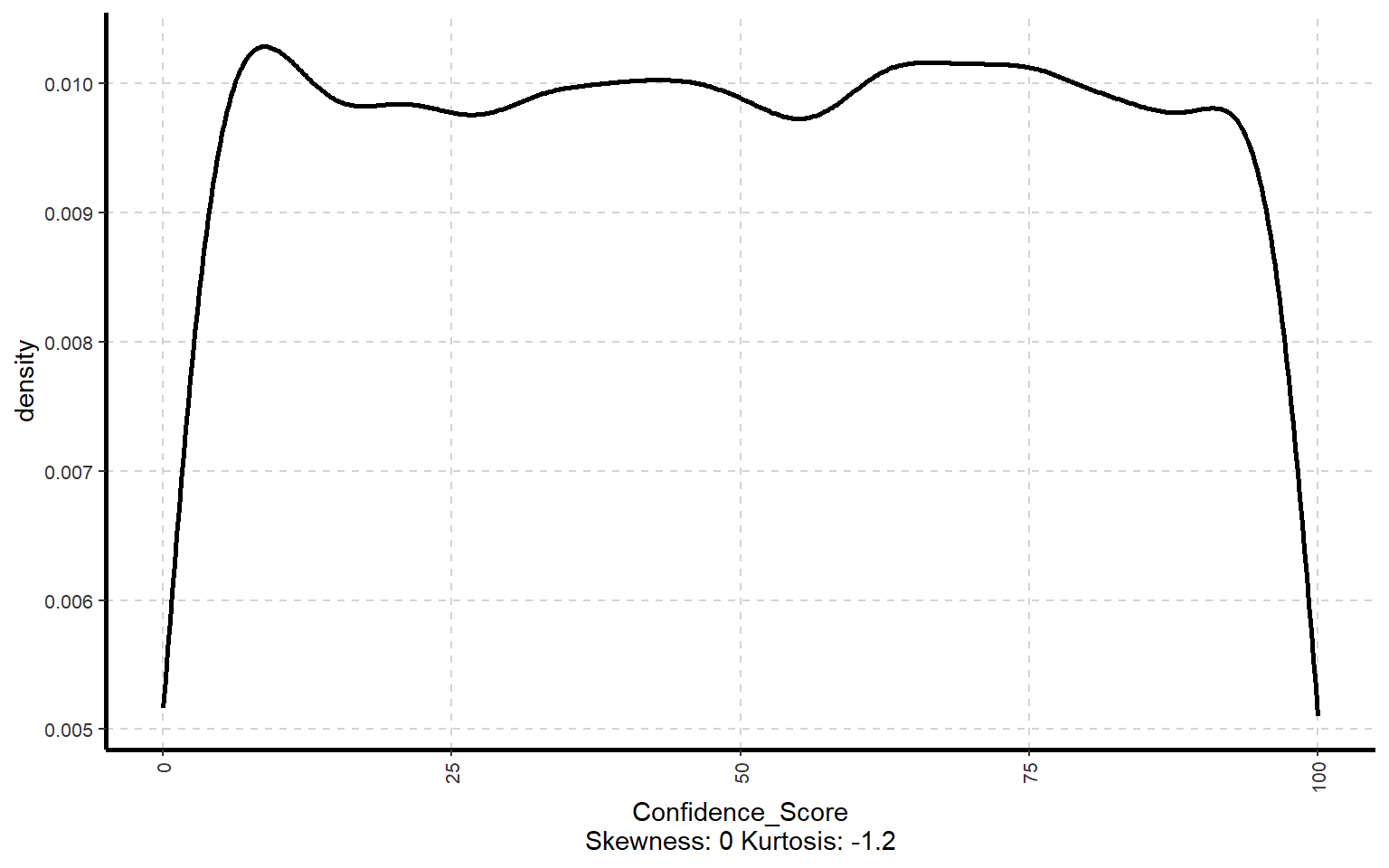
10.2 Generate Density plot
# Curvas de densidad de las variables numéricasExpNumViz(dades, target =NULL, type =3, nlim =25)
[[1]]
[[2]]
[[3]]
[[4]]
10.3 Generate Scatter plot
# Gráficos de dispersión utilizando Age como variable objetivoExpNumViz(dades, target ="Age", type =3, nlim =25)
[[1]]
[[2]]
[[3]]
[[4]]
11 Summary of Categorical variables
11.1 Frequency or custom tables for categorical variables
# Tablas de frecuencias de variables categóricasExpCTable( dades,Target =NULL,margin =1,clim =10,nlim =5,round =2,bin =NULL,per =TRUE)
11.2 Summary statistics of categorical variables
# Resumen estadístico de variables categóricas respecto a Valentine_DateExpCatStat( dades,Target ="Valentine_Date",result ="Stat",clim =10,nlim =5,Pclass ="Yes")
11.3 Information value and Odds value
# Cálculo del Information Value (IV), útil en selección de variablesExpCatStat( dades,Target ="Valentine_Date",result ="IV",clim =10,nlim =5,Pclass ="Yes")
Este punto es muy interesante desde la perspectiva de Machine Learning, ya que el Information Value ayuda a valorar la capacidad predictiva de variables categóricas respecto a una variable objetivo.
12 Graphical representation of all categorical variables
12.1 Column chart
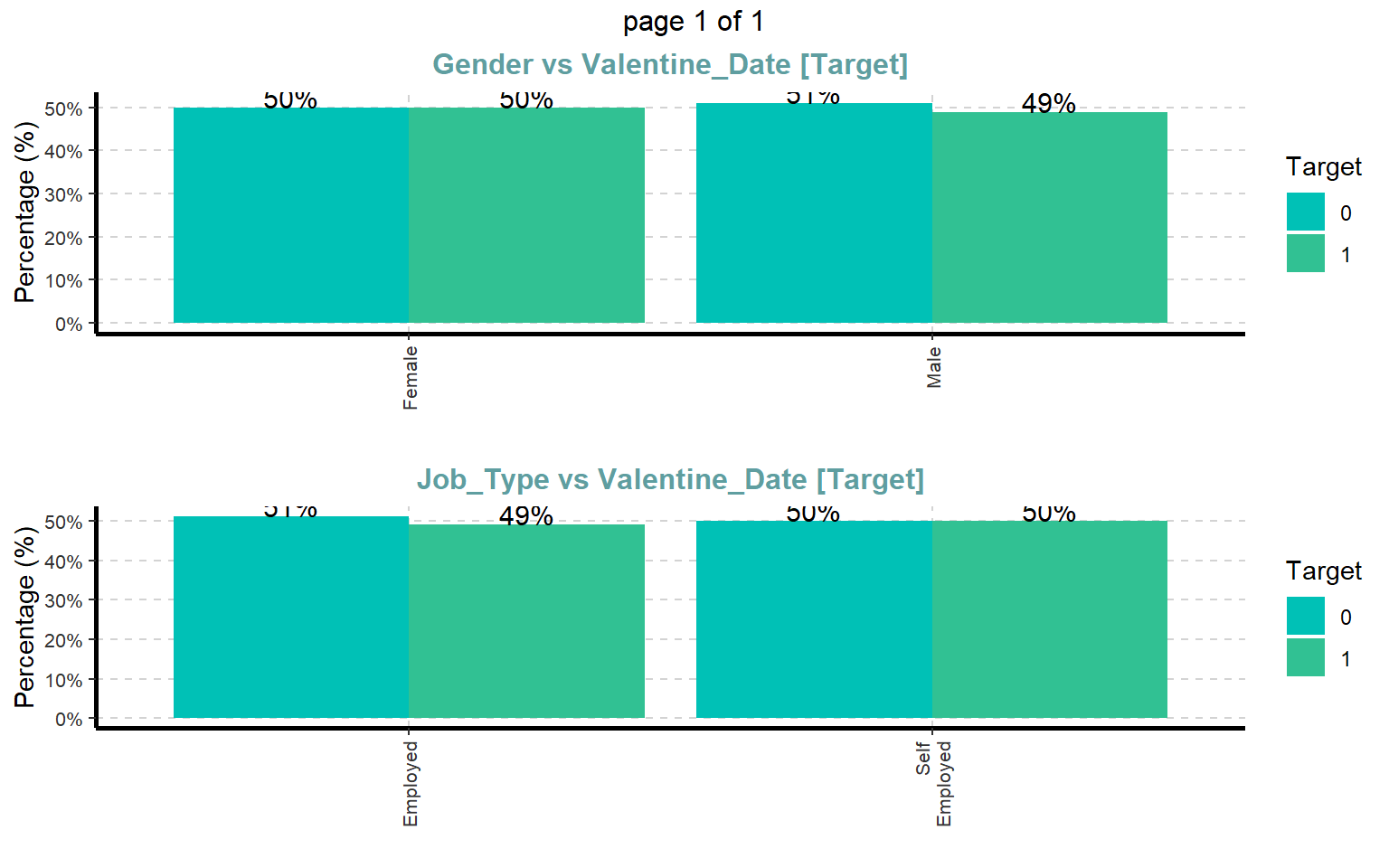
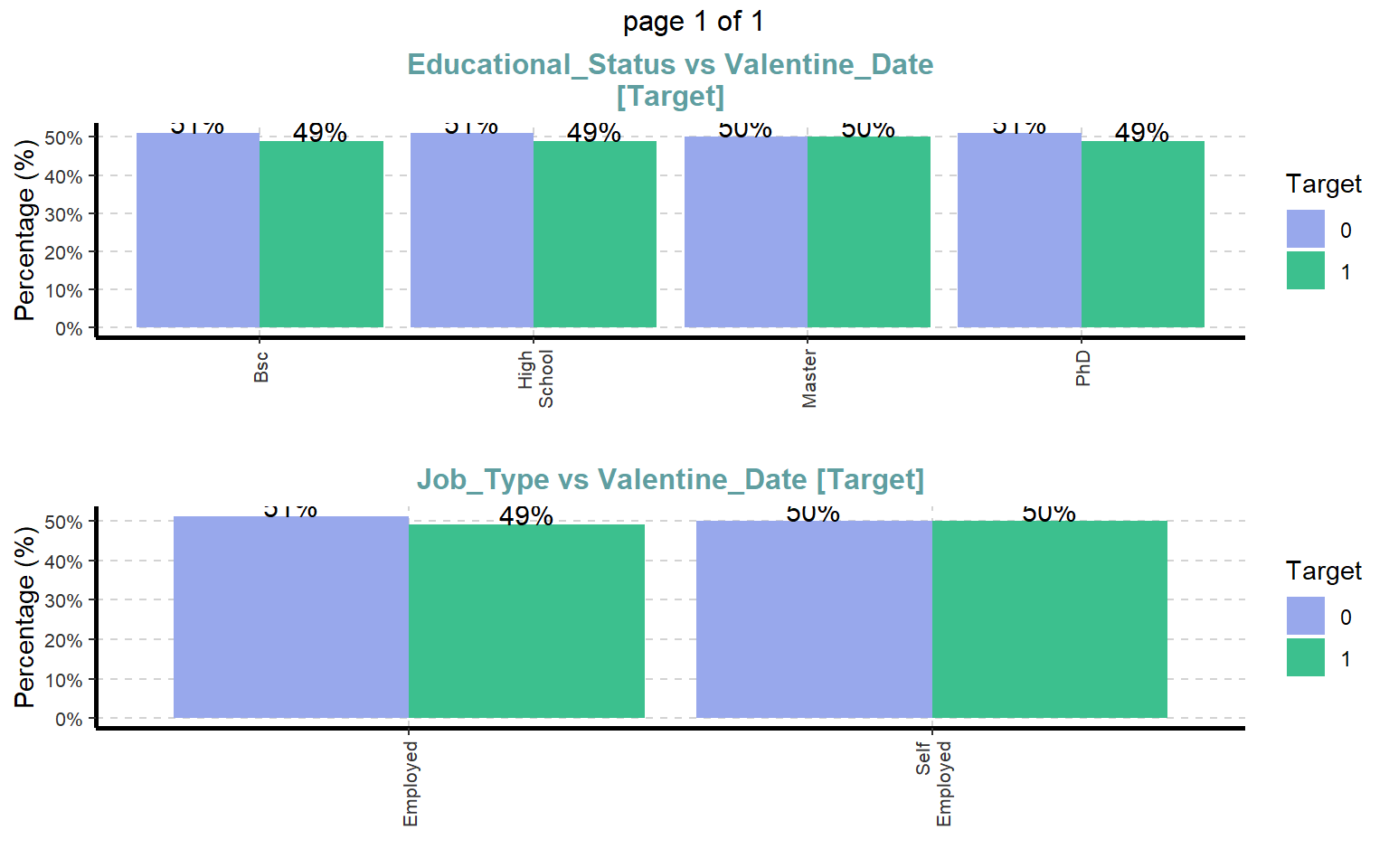
# Gráficos de barras para variables categóricas respecto a la variable objetivoExpCatViz( dades,target ="Valentine_Date",fname =NULL,clim =10,col =NULL,margin =2,Page =c(2, 1),sample =2)
$`0`
12.2 Stacked bar graph
# De nuevo, representación visual de variables categóricas en formato apiladoExpCatViz( dades,target ="Valentine_Date",fname =NULL,clim =10,col =NULL,margin =2,Page =c(2, 1),sample =2)
$`0`
13 Variable importance based on Information value
# Importancia de variables categóricas basada en Information ValueExpCatStat( dades,Target ="Valentine_Date",result ="Stat",clim =10,nlim =5,bins =10,Pclass ="Yes",plot =TRUE,top =10,Round =2)
Este bloque permite destacar las variables con mayor relevancia respecto a la variable objetivo.
14 Conclusiones docentes
A través de este guion hemos trabajado distintas formas de realizar una EDA automática en R.
La idea fundamental que debe interiorizar el alumnado es que, antes de entrenar modelos de Machine Learning, conviene responder preguntas como:
¿qué tipos de variables tengo?,
¿hay valores ausentes?,
¿cómo se distribuyen las variables?,
¿hay relaciones importantes entre ellas?,
¿qué variables parecen más informativas?
Una buena EDA reduce errores posteriores y mejora la calidad del proceso analítico.
Aquesta web està creada por Dante Conti y Sergi Ramírez, (c) 2026
Ejecutar el código
---title: "Preprocessing: Descriptiva Automàtica"subtitle: "EDA automática con R"author: - "Sergi Ramírez" - "Dante Conti"format: html: theme: cosmo toc: true toc-depth: 3 number-sections: true code-fold: false code-tools: true df-print: paged fig-width: 8 fig-height: 5execute: echo: true warning: false message: false cache: falselang: eseditor: visual---# IntroducciónEn este script trabajamos la **descriptiva automática** o **EDA (Exploratory Data Analysis)** utilizando varias librerías de R especializadas en exploración rápida de datos.El objetivo docente de esta práctica es que el alumnado sea capaz de:- entender la estructura de una base de datos antes de modelizar,- identificar variables numéricas y categóricas,- detectar valores perdidos,- estudiar correlaciones,- generar reportes automáticos de apoyo al análisis.A lo largo del documento se respetará al máximo la estructura del script original, pero añadiendo **comentarios explicativos** para que pueda utilizarse directamente como material de laboratorio.# PREPROCESSING: Descriptiva Automàtica## Carreguem les llibreriesEn primer lugar cargamos las librerías necesarias. Cada una aporta una funcionalidad distinta dentro del proceso de exploración automática.```{r}# visdat: visualización estructural del dataset y de los valores perdidos# inspectdf: diagnóstico rápido de tipos, memoria, missing values y distribuciones# skimr: resumen descriptivo automático muy útil en una primera inspección# tidyverse: manipulación de datos con dplyr, pipes y utilidades de visualizaciónlist.of.packages <-c("visdat", "inspectdf", "skimr", "tidyverse", "dataReporter", "DataExplorer", "SmartEDA")# Detectamos qué paquetes no están instalados.new.packages <- list.of.packages[!(list.of.packages %in%installed.packages()[, "Package"])]# Instalamos los que falten.if (length(new.packages) >0) {install.packages(new.packages)}# Cargamos todas las librerías en memoria.lapply(list.of.packages, require, character.only =TRUE)# Eliminamos objetos auxiliares del entorno.rm(list.of.packages, new.packages)```## Carreguem les bases de dadesCargamos la base de datos que vamos a analizar. En este caso se utiliza el fichero `valentine_dataset.csv`.```{r}# Lectura del dataset desde la carpeta de trabajopath <-"https://ramia-lab.github.io/AdvancedModelling/material/01_AdvancedPreprocessing/laboratorio/valentine_dataset.csv"dades <-read.csv(path)```Antes de profundizar, puede ser útil inspeccionar rápidamente las primeras filas.```{r}# Visualización inicial de las primeras observacioneshead(dades)```# Paquete SkimLa librería `skimr` permite obtener un resumen automático muy completo del dataset. Es especialmente útil como primer diagnóstico global.## Podem visualitzar un descriptiu de les dades```{r}# Resumen general de todas las variables del datasetskim(dades)```Este resumen permite identificar de forma muy rápida:- número de observaciones,- tipo de variables,- número de valores perdidos,- estadísticos descriptivos básicos.## Visualitzem exclusivament les variables numèriques```{r}# Extraemos únicamente el resumen de las variables numéricasskim(dades) %>%yank("numeric")```Aquí el alumnado puede fijarse especialmente en:- media,- desviación típica,- percentiles,- posibles asimetrías o rangos extremos.## Visualitzem exclusivament les variables categòriques```{r}# Extraemos únicamente el resumen de las variables categóricas o de textoskim(dades) %>%yank("character")```En este caso interesa observar:- número de categorías distintas,- frecuencia de la categoría más repetida,- posibles problemas de codificación o cardinalidad elevada.# Paquete VisdatLa librería `visdat` está orientada a la **visualización de la estructura de los datos** y de los **missing values**.## Busquem per a variables numèriques o categòriques si hi ha NA's```{r}# Mapa general de tipos de dato y valores ausentesvis_dat(dades)```Este gráfico permite detectar visualmente:- qué tipo tiene cada variable,- si existen patrones de valores perdidos,- si hay mezclas inesperadas de tipos.## Visualitzem percentatges de NA's en les variables```{r}# Representación específica del porcentaje y localización de valores perdidosvis_miss(dades)```Pedagógicamente, este gráfico es muy útil para discutir si conviene:- imputar valores,- eliminar variables,- eliminar registros,- estudiar el mecanismo de missingness.## Generem la matriu de correlacionsPara generar la matriz de correlaciones necesitamos quedarnos solo con las variables numéricas.```{r}# Seleccionamos las variables numéricas y representamos sus correlacionesdades %>%select(where(is.numeric)) %>%vis_cor()```Este paso es importante porque:- permite detectar relaciones lineales entre variables,- ayuda a identificar redundancia de información,- anticipa posibles problemas de multicolinealidad.## Podem visualitzar condicionants de les dades. En aquest cas, mirem si tenim més de 2 classes`vis_expect()` permite verificar si los datos cumplen una determinada condición lógica.```{r}# Comprobamos visualmente qué valores cumplen la condición x > 2vis_expect(dades, ~ .x >2)```Este tipo de función resulta útil para construir reglas de validación y control de calidad del dato.# InspectdfLa librería `inspectdf` ofrece un diagnóstico compacto y visual del dataset. Es muy adecuada para docencia porque transforma resúmenes complejos en gráficos interpretables.## Tipus de dades```{r}# Inspección de los tipos de variables presentes en la base de datosinspect_types(dades) %>%show_plot()```Aquí se puede discutir con el alumnado:- si los tipos son coherentes,- si alguna variable debería recodificarse,- si hay variables de texto que realmente son categóricas.## Utilització de la memoria```{r}# Análisis del consumo de memoria por variableinspect_mem(dades) %>%show_plot()```Este análisis es especialmente interesante cuando se trabaja con bases de datos grandes, ya que ayuda a detectar variables costosas en almacenamiento.## Comprovem NA'sCreamos una variable auxiliar (`price_dummy`) a partir de la renta (`Income`) para comparar patrones de missing values entre dos grupos.```{r}# Creamos una variable categórica auxiliar según el nivel de ingresosdata_price_dummy <- dades %>%mutate(price_dummy =if_else(Income >10000, "High", "Low"))``````{r}# Comparamos los NA's entre el grupo de renta alta y el grupo de renta bajainspect_na(data_price_dummy %>%filter(price_dummy =="High"), data_price_dummy %>%filter(price_dummy =="Low")) %>%show_plot()```Esta comparación permite introducir una idea importante: los valores ausentes no siempre se distribuyen de forma homogénea entre subgrupos de la población.## Comprovem la distribució de les variables```{r}# Resumen visual de la distribución de variables numéricasinspect_num(dades) %>%show_plot()```Este gráfico ayuda a revisar:- dispersión,- asimetría,- presencia de valores extremos,- comportamiento global de las variables cuantitativas.## Check categorical variable distribution```{r}# Estudio del desbalance o distribución de las variables categóricasinspect_imb(dades) %>%show_plot()```Esto resulta especialmente útil para:- detectar clases muy desbalanceadas,- preparar problemas de clasificación,- valorar si una categoría tiene muy poca representación.## Check two categoricalComparamos de nuevo dos subconjuntos del dataset definidos por la variable `price_dummy`.```{r}# Comparación del desbalance categórico entre dos subgruposinspect_imb(data_price_dummy %>%filter(price_dummy =="High"), data_price_dummy %>%filter(price_dummy =="Low")) %>%show_plot() +theme(legend.position ="none")```En términos docentes, este paso permite mostrar que la composición categórica puede variar mucho entre grupos.## Similar to inspect_imb, but for all levels```{r}# Visualización completa de todas las categorías presentes en cada variable cualitativainspect_cat(dades) %>%show_plot()```Esto permite estudiar con más detalle la frecuencia de cada nivel categórico.## Correlacions```{r}# Gráfico resumido de correlaciones entre variables numéricasinspect_cor(dades) %>%show_plot()```De nuevo, este análisis refuerza la importancia de estudiar relaciones entre variables antes de pasar a una fase de modelización.# dataReporter (antiguo dataMaid)La librería `dataReporter` permite generar documentación automática del dataset, muy útil cuando se quiere dejar trazabilidad del análisis.## Generació d'un informe automàtic```{r}#| eval: false# Generamos un informe HTML automático con información descriptiva del datasetdataReporter::makeDataReport( dades,output ="html",file ="report.Rmd")```## Generació d'un codebook```{r}#| eval: false# Generamos un codebook o diccionario automático del conjunto de datosdataReporter::makeCodebook(data = dades,file ="codebook.Rmd")```Observación docente: en el script original aparecían rutas absolutas del sistema local. Aquí se han sustituido por rutas relativas para que el material sea portable y reutilizable en clase.# DataExplorer`DataExplorer` es una de las librerías más prácticas para realizar una exploración rápida y visual del dataset.## Estructura general del dataset```{r}# Representación de la estructura del datasetplot_str(dades)# Resumen introductorio del conjunto de datosintroduce(dades)# Visualización gráfica introductoriaplot_intro(dades)```Estos comandos son útiles para una primera fotografía global de la base de datos.## Missing values```{r}# Visualización de valores ausentesplot_missing(dades)```## Variables categóricas```{r}# Diagramas de barras para variables categóricasplot_bar(dades)# Barras condicionadas por la variable Ageplot_bar(dades, with ="Age")# Barras agrupadas por la variable Genderplot_bar(dades, by ="Gender")```Aquí se puede trabajar en clase:- interpretación de frecuencias,- relación entre variables categóricas,- patrones segmentados por grupo.## Variables numéricas```{r}# Histogramas automáticos de las variables numéricasplot_histogram(dades)```## Correlacions```{r}# Mapa de correlaciones eliminando previamente los NA'splot_correlation(na.omit(dades), maxcat =5L)```Se utiliza `na.omit()` porque muchas funciones de correlación requieren una matriz sin valores ausentes.# SmartEDALa librería `SmartEDA` combina resúmenes estadísticos con visualizaciones y tablas interpretables. Es especialmente útil cuando se quiere una exploración semiautomática más detallada.## Overview of the data```{r}# Vista general del datasetExpData(data = dades, type =1)```## Structure of the data```{r}# Estructura del dataset: tipos, dimensiones y composiciónExpData(data = dades, type =2)```# Summary of numerical variables## Summary statistics by – overall```{r}# Estadísticos descriptivos globales para variables numéricasExpNumStat( dades,by ="A",gp =NULL,Qnt =seq(0, 1, 0.1),MesofShape =2,Outlier =TRUE,round =2)```Este comando devuelve medidas como:- media,- mediana,- cuantiles,- curtosis,- asimetría,- detección de posibles outliers.## Summary statistics by – overall with correlation```{r}# Estadísticos descriptivos incorporando una variable de agrupaciónExpNumStat( dades,by ="A",gp ="Age",Qnt =seq(0, 1, 0.1),MesofShape =1,Outlier =TRUE,round =2)```Aunque `Age` sea numérica, aquí se está utilizando como referencia de agrupación dentro del análisis.## Summary statistics by – category```{r}# Estadísticos numéricos segmentados por la categoría GenderExpNumStat( dades,by ="GA",gp ="Gender",Qnt =seq(0, 1, 0.1),MesofShape =2,Outlier =TRUE,round =2)```Esto permite comparar el comportamiento de las variables numéricas entre grupos categóricos.# Graphical representation of all numeric features## Generate Boxplot by category```{r}# Boxplots de variables numéricas segmentadas por GenderExpNumViz(dades, target ="Gender", type =2, nlim =25)```## Generate Density plot```{r}# Curvas de densidad de las variables numéricasExpNumViz(dades, target =NULL, type =3, nlim =25)```## Generate Scatter plot```{r}# Gráficos de dispersión utilizando Age como variable objetivoExpNumViz(dades, target ="Age", type =3, nlim =25)```# Summary of Categorical variables## Frequency or custom tables for categorical variables```{r}# Tablas de frecuencias de variables categóricasExpCTable( dades,Target =NULL,margin =1,clim =10,nlim =5,round =2,bin =NULL,per =TRUE)```## Summary statistics of categorical variables```{r}# Resumen estadístico de variables categóricas respecto a Valentine_DateExpCatStat( dades,Target ="Valentine_Date",result ="Stat",clim =10,nlim =5,Pclass ="Yes")```## Information value and Odds value```{r}# Cálculo del Information Value (IV), útil en selección de variablesExpCatStat( dades,Target ="Valentine_Date",result ="IV",clim =10,nlim =5,Pclass ="Yes")```Este punto es muy interesante desde la perspectiva de Machine Learning, ya que el **Information Value** ayuda a valorar la capacidad predictiva de variables categóricas respecto a una variable objetivo.# Graphical representation of all categorical variables## Column chart```{r}# Gráficos de barras para variables categóricas respecto a la variable objetivoExpCatViz( dades,target ="Valentine_Date",fname =NULL,clim =10,col =NULL,margin =2,Page =c(2, 1),sample =2)```## Stacked bar graph```{r}# De nuevo, representación visual de variables categóricas en formato apiladoExpCatViz( dades,target ="Valentine_Date",fname =NULL,clim =10,col =NULL,margin =2,Page =c(2, 1),sample =2)```# Variable importance based on Information value```{r}# Importancia de variables categóricas basada en Information ValueExpCatStat( dades,Target ="Valentine_Date",result ="Stat",clim =10,nlim =5,bins =10,Pclass ="Yes",plot =TRUE,top =10,Round =2)```Este bloque permite destacar las variables con mayor relevancia respecto a la variable objetivo.# Conclusiones docentesA través de este guion hemos trabajado distintas formas de realizar una **EDA automática** en R. La idea fundamental que debe interiorizar el alumnado es que, antes de entrenar modelos de Machine Learning, conviene responder preguntas como:- ¿qué tipos de variables tengo?,- ¿hay valores ausentes?,- ¿cómo se distribuyen las variables?,- ¿hay relaciones importantes entre ellas?,- ¿qué variables parecen más informativas?Una buena EDA reduce errores posteriores y mejora la calidad del proceso analítico.# Bibliografia- <https://www.analyticsvidhya.com/blog/2022/10/three-r-libraries-for-automated-eda/>- <https://cran.r-project.org/web/packages/dlookr/vignettes/EDA.html>- <https://cran.r-project.org/web/packages/DataExplorer/vignettes/dataexplorer-intro.html>- <https://daya6489.github.io/SmartEDA/>